浅谈数据库事务违背隔离性错误
梳理数据库事务并发调度过程中可能遇到的各种违背隔离性错误。
关键词:隔离性、隔离性错误
事务隔离性
隔离性(Isolation),一个事务执行应该是独立的,在执行过程中并不需要和其他事务交互。换句话说,一个事务不应该看到另外一个事务的“中间态”结果,也不应该基于该“中间态”结果实现自身后续操作。一旦违背这一原则,就会出现各种不同的违背隔离性错误。
除了少部分单线程数据库(比如 redis)之外,大部分数据库系统是多线程并发调度事务。多个线程访问到同一个对象的时候,这就出现了竞态条件(race condition)。所以,解决事务“隔离性”本质上,是解决多线程竞态调度问题。换句话说,保证事务隔离性,就是数据库系统帮助应用层封装并发访问数据的复杂度,并保证应用层并发提交的事务最终执行的结果跟串行化调度执行的结果一致。
而应用层所得到的好处,它可以假设,自己每次提交的事务都是排他性访问资源,不用担心会读取到别的事务的中间结果,只需要写好一个事务的操作即可,无需担心并发问题。当然该假设是针对串行化隔离级别才生效。
违背隔离性错误
一旦违背数据库隔离性要求的原则,就可能出现各种隔离性错误:
- 脏写
- 脏读
- 不可重复读
- 幻影
- 幻读
- 写偏斜
- 丢失更新
接下来会逐一讲解每一类错误。
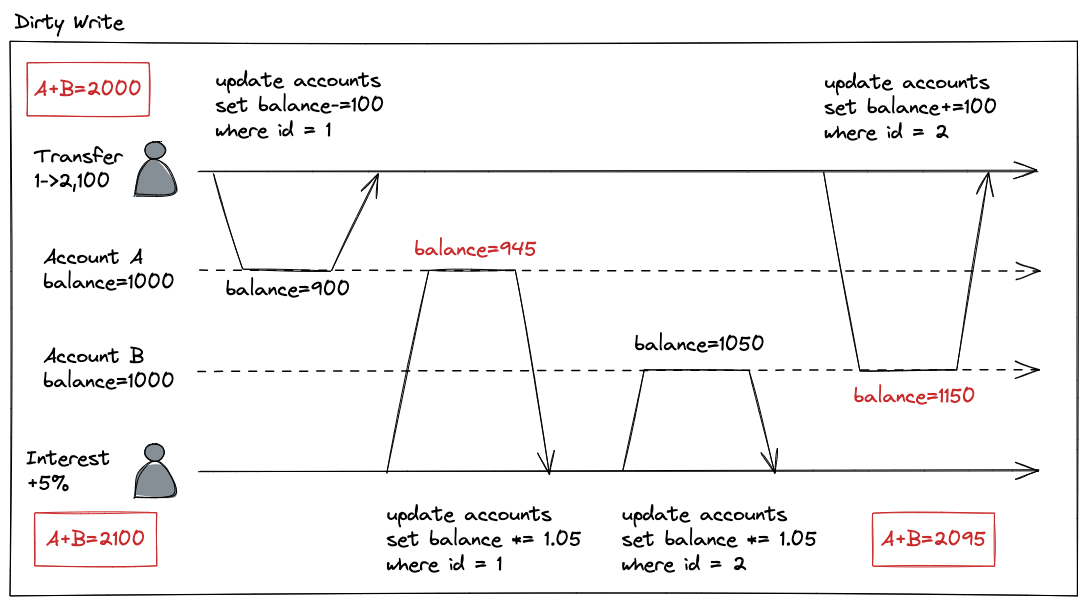
脏写(Dirty Write)
两个事务并发写,其中一个事务的写入操作覆盖另外一个事务未提交的写入结果。这通常会导致写入结果混合。
- T1 刚操作 A 转出 100
- T2 就看到 T1 的“中间态”结果按照 900 来计算利息,得到 A 的最终结果 945 元
- T2 又先执行 B 的年度利息,得到 1050 元
- 最后 T1 再将 100 转给 B,得到最终 B 的结果 1150 元
- 最终总余额是 2095 元
但是按照串行化调度,不管是 T1->T2,抑或是 T2->T1,最终总余额都应该是:2100元,少了 5 元。这里出现了不符合预期的结果,而问题就出在了第二步,T2 读取了(read from) T1 未提交的写入结果,导致两个事务结果混合了。流程如下图所示:
脏读(Dirty Read)
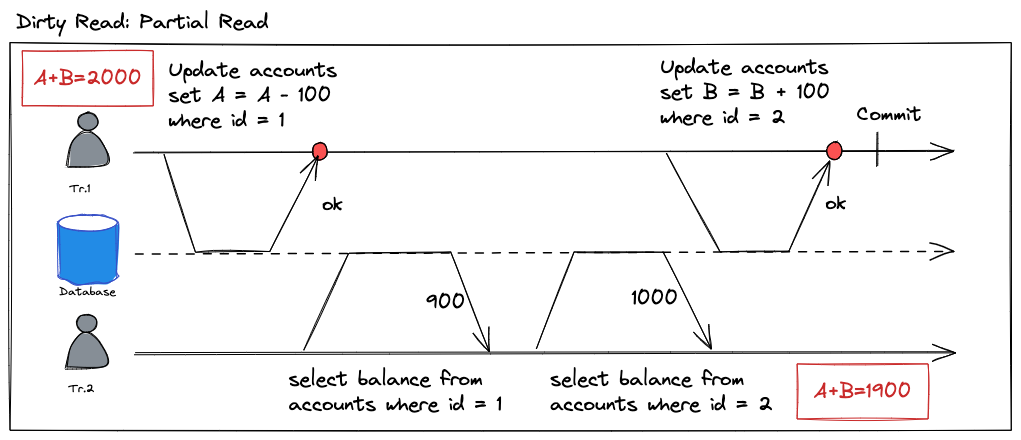
一个事务(T1)写入多个数据对象过程中,另外一个事务(T2)读取了 T1 执行了一部分操作的结果。那么 T2 就会出现“脏读”问题。
- T1 从A账户扣减 100 元
- T2 读取了 T1 执行了一半的结果,拿到 A 对象结果是 900元
- T2 拿到 B 对象结果是 1000 元
- T2 合计总余额是 1900元
- T1 为B账户增加 100元
但是按照串行化调度,不管是 T1->T2,抑或是 T2->T1,T2读取到总余额都应该是 2000元。这里出现了不符合预期的结果,问题就是出在了第二步,T2 读取了 T1 未提交的写入结果。流程图如下所示:
不可重复读(Non-Repeatable Read)
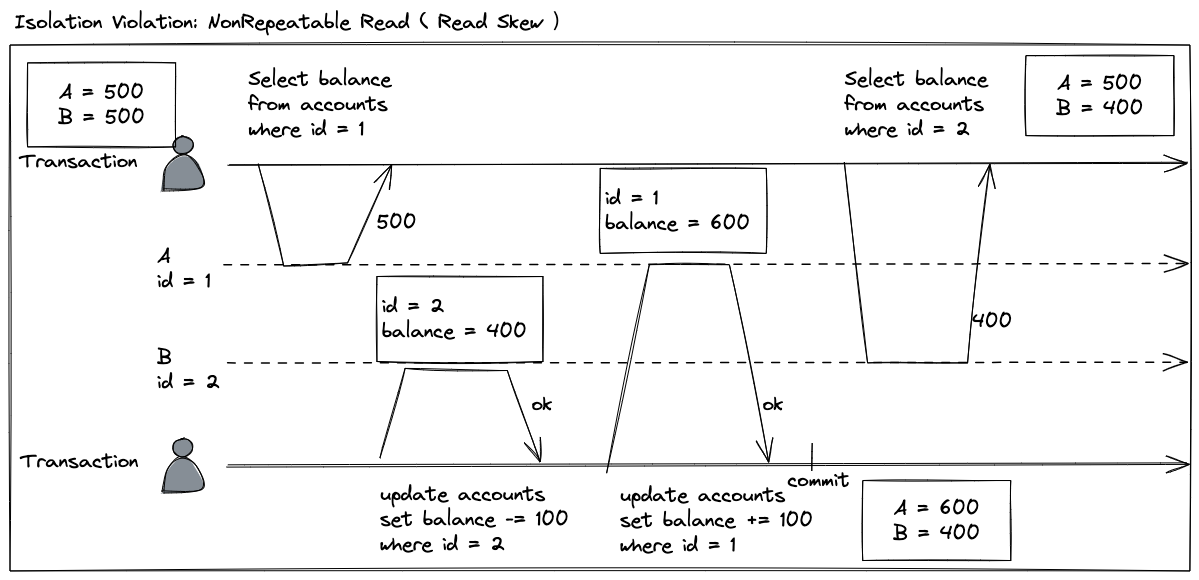
一个事务(T1)读取数据对象的过程中,另外一个事务(T2)写入同样的数据对象并成功提交,这会导致事务 T1 两次读取的数据出现不一致的情况。这个问题就叫做:“不可重复读”。
比如,一个用户两个银行账号间的转账操作流程:
- 一个用户在一家银行有两张账户卡(A 和 B),两张卡余额总和是 1000 元
- 现在他从账户 B 转移 100 元到账户 A
- T1 开始读取,账户 A 余额 500
- T2 执行写入操作,从账户 B 转账 100元 给账户 A,并提交
- 此时,A:600,B:400
- T1 继续读取,由于 T2 已经提交,所以 T1 第二次读取并未破坏读已提交要求,但是拿到账户B已提交结果的余额就是 400
- 最终,用户看到的他的余额是 900 元,数据错误
具体操作时序如下图所示:
这里的结果看起来跟脏读(Dirty Read)有些类似,但实际上是完全不同的,核心不同就在于,“是否读取了未提交的结果”:
- 脏读,是读取了未提交的写入结果,导致读取的事务数据错误;
- 不可重复读,两次读取的都是已提交结果,但是依然会出现数据错误;
所以,读已提交隔离级别下,未能解决的“不可重复读”问题。
幻影(Phantom)、幻读(Phantom Read)、写偏斜(Write Skew)
一个事务写入操作(更新、插入、删除)会影响另外一个事务读取结果,这个就叫做“幻影”(Phantom)。
幻影在一个只读事务,表现为“幻读”(Phantom Read)问题。在读写混合的事务中,会出现“写偏斜”(Write Skew)问题。
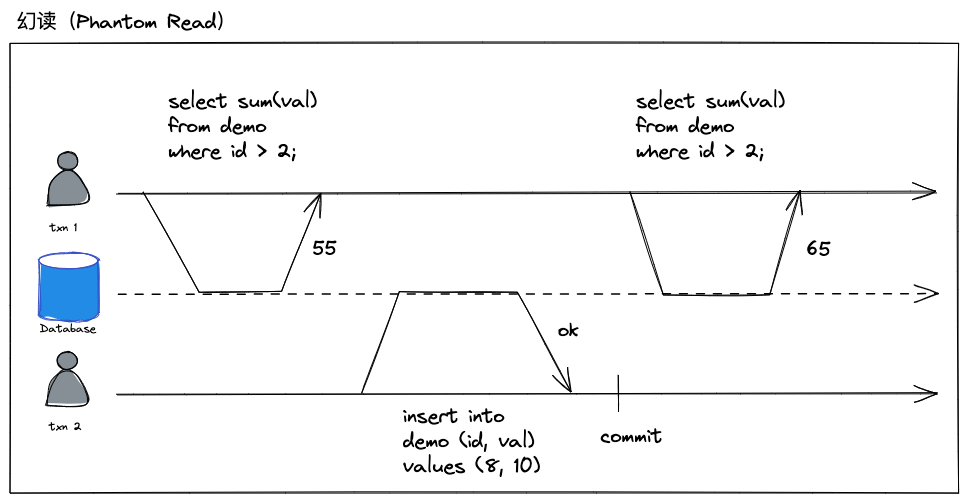
幻读(Phantom Read)
在一个事务(T1)执行查询事务过程中,另外一个事务(T2)插入数据记录,T2的改动又满足T1查询条件,就会T1两次查询出来的结果不一样,就像出现幻影一样。
比如,以下例子:
- T1 第一次执行查询,得到结果55
- T2 执行插入操作,写入一条新的数据,并已提交
- T1 再次执行查询,会把新的数据一并累加进来,得到结果65
- T1 一个事务内,前后两次同样条件的查询,却得到不同的结果,就像出现幻影一般
操作时序如下图所示:
事务 T1,遇到的问题就叫做幻读(Phantom Read)。那么,幻读和不可重复读有什么区别呢?核心区别就在于:“是否新增数据行”
- 不可重复读,读取的数据对象,已存在,被其他事务更新导致错误
- 幻读,读取过程,出现新增记录,导致数据错误
写偏斜(Write Skew)
“写偏斜”问题,是“read-modify-update”的场景,是“丢失更新”问题一般化表现,写偏斜问题有着更加隐蔽的竞态条件(race condition)。“写偏斜”只在读取的时候有交集,写操作的数据对象没有交集,不同事务各自对自己取出来的数据集合中的一部分数据进行更新,各自更新的部分没有交集。
考虑以下业务场景:客服值班过程,允许客服人员中途申请休息,但是至少要保证有一名客服在线。
现在,有一张值班表(dutytable)记录每个客服人员当前状态(true 表示空闲,false 表示在忙)。
- 此刻,xyz 和 abc 是两位空闲的客服人员,他们同时发起休息申请
- 业务获取到的空闲人数都是 2,只要事务 1 没有提交,按照快照隔离实现方案来说,事务 2 在这期间拿到的数据,同样会是 2。
- 所以,基于业务约束条件:“至少要有一位客服值班”,这两位客服人员的休息申请都能通过,接下来他们将各自的值班状态更改为”在忙“(false)。
- 但是,最后的结果是,没有一位客服在值班。
具体执行流程如下图所示:
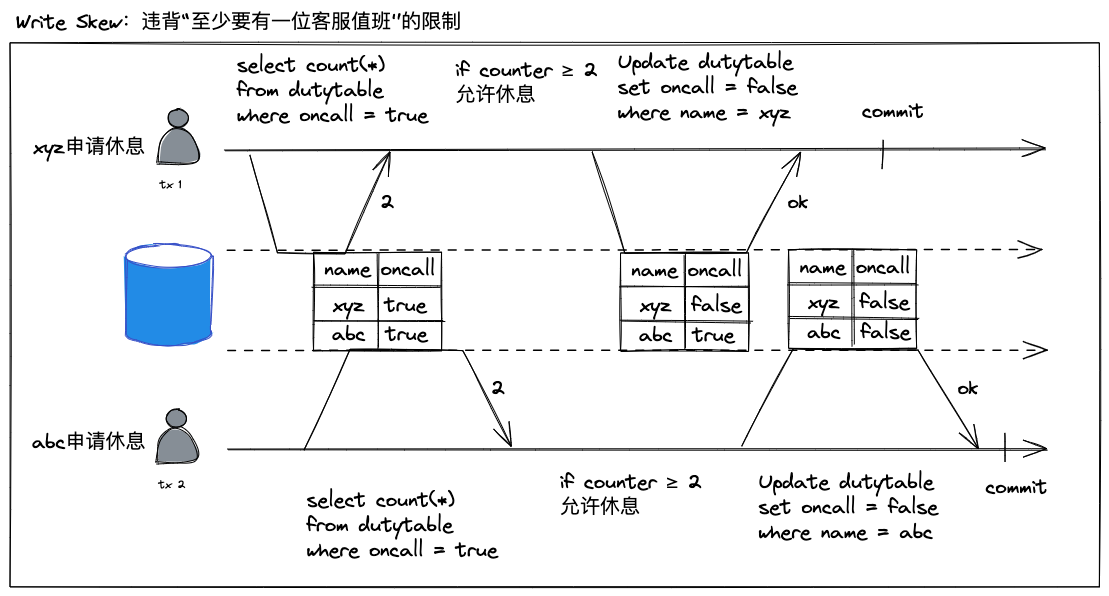
这里麻烦点就在于,两个客服是更新各自记录的状态,那么哪怕是用上版本号(version)做乐观锁设计依然是卡不住的。基于版本号实现的乐观锁设计只能解决同一行的记录的并发更新问题,也就是“丢失更新”问题。
只从数据库系统的角度去考虑上述问题的解决方案,那就是在查询的时候上锁,并且数据库系统还得支持范围锁。
MySQL InnoDB 引擎,可以使用 “select…for update” 语句,在查询的时候上锁,并且 MySQL InnoDB 会用上范围锁实现,将满足条件的都上锁。那么,事务 T2 在这个场景只能等待事务 T1 提交后才能执行。
丢失更新(Lost Updates)
从数据库读取出来一些数据,根据业务需要做一些修改,再给写回去,也就是通常所说的“read-modify-write”操作。但就是这么简单一种应用场景,在并发情况下,依然会出错,后写的事务会消除先写事务的写入结果,从而导致丢失更新的情况。
考虑以下示例:
- 事务 T1 查询 id = 1 记录,得到 42,应用层累加得到 43
- 事务 T2 查询 id = 1 记录,得到 42,同样地累加后得到 43
- 事务 T1 更新写入结果,并提交,结果 43
- 事务 T2 更新写入结果,并提交,结果 43
- 但是,这里少累加了一次,
示例如下图:
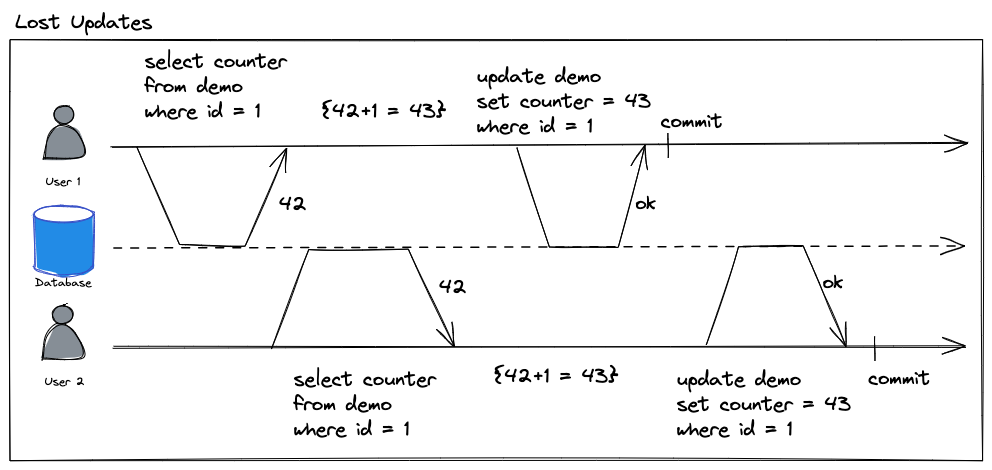
以上例子中 ,两个事务都想读取原来的数据,并累加 1,如果按照串行化执行顺序最终的结果应该是 44,可最终得到的却是 43,这里出现了丢失更新的问题。
这个问题和“脏写”是不一样的,脏写是覆盖未提交的数据。但在这个场景中,事务 T2 是在事务 T1 提交成功之后才提交,并未覆盖未提交,最终结果就像是将事务 T1 的写入结果消除掉了,事务 T1 从未发生一样,所以才叫做“丢失更新”问题。
总结
数据库事务隔离性,本质上还是多线程并发调度问题。调度过程中,遇到的读写冲突一旦没有处理好,就会带来上述的各种问题,这些问题就叫做违背隔离性错误。清晰各类错误定义以及边界,可以帮助你快读定位业务场景中遇到的实际问题,并以此找到对应的解决方案。
参考文献
- CMU 15-445 Fall 2019 16 Concurrency Control Theory - youtube - video 43:02
- Designing Data-Intensive Applications 07 Transactions