两阶段锁、死锁处理以及锁粒度
两阶段锁,是一套并发控制协议,数据库系统实现该协议可以保证事务并发调度的隔离性。当然,这套协议并不是简单的上锁、释放锁两个操作,还会涉及到死锁处理、锁粒度设计等等问题。
关键词:两阶段锁、死锁检测、死锁预防、锁分层结构、意图锁。
两阶段锁(2PL)、强严格两阶段锁(Rigorous 2PL, SS2PL)
两阶段锁(2PL)
两阶段锁,是一套并发控制协议。其核心思路,一个事务分为锁增长和锁释放两个阶段,并基于读写操作互斥原则保护共享资源,从而实现并发事务的串行化调度。
- 锁增长阶段(Grow):事务会依据操作申请读锁、写锁,这个过程不会释放任何锁
- 锁释放阶段(Shrink):允许释放之前获取的所有锁,同时不能获取新的锁
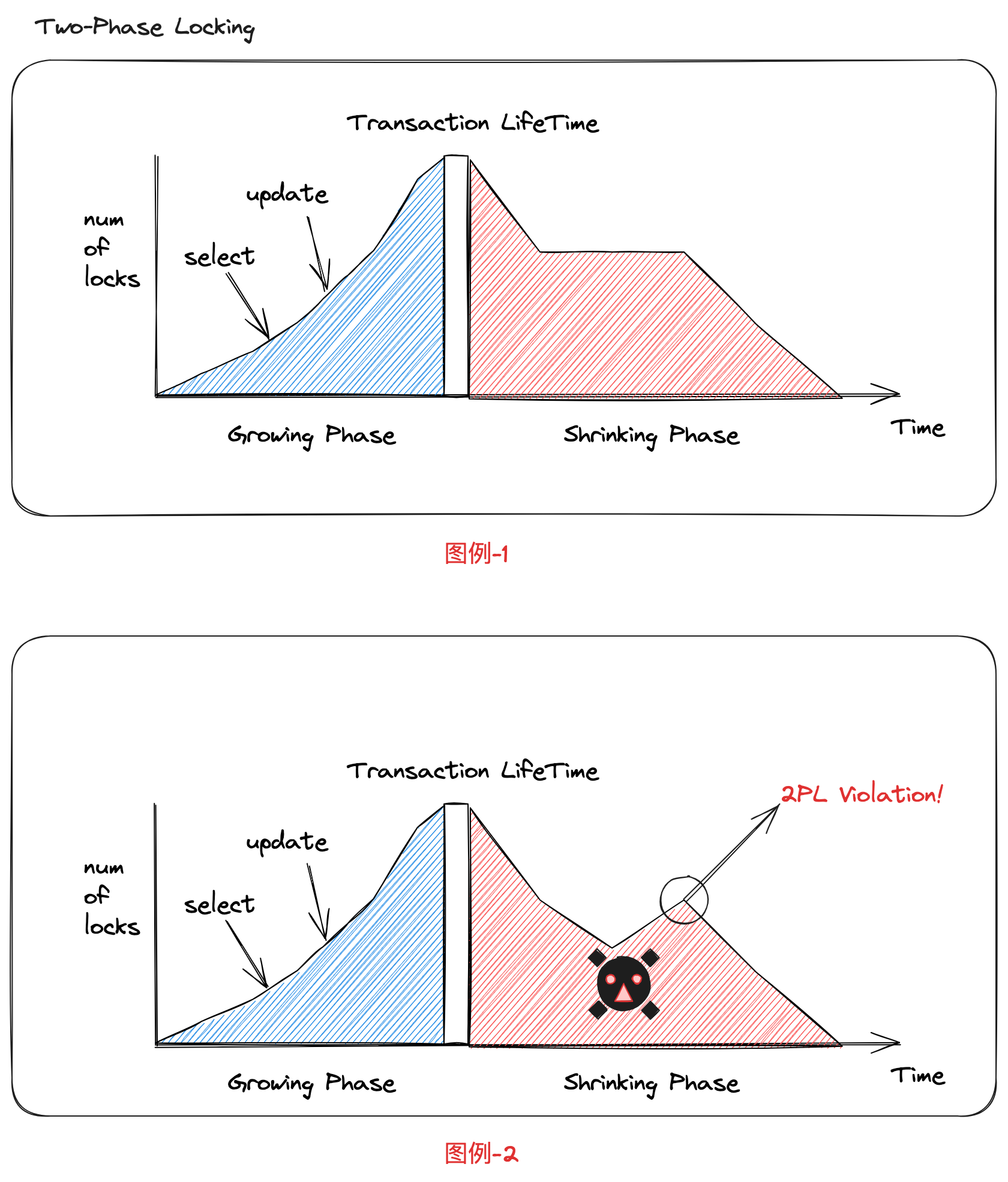
图例-2的问题就在于,在锁释放阶段还申请了新的锁资源,这是不被允许的。
级联回滚(Cascading Aborts)
当然,协议有一个漏洞,那就是当发生回滚的时候,如果不做处理,就可能出现“脏读(Dirty Read)”问题。
观察以下例子:
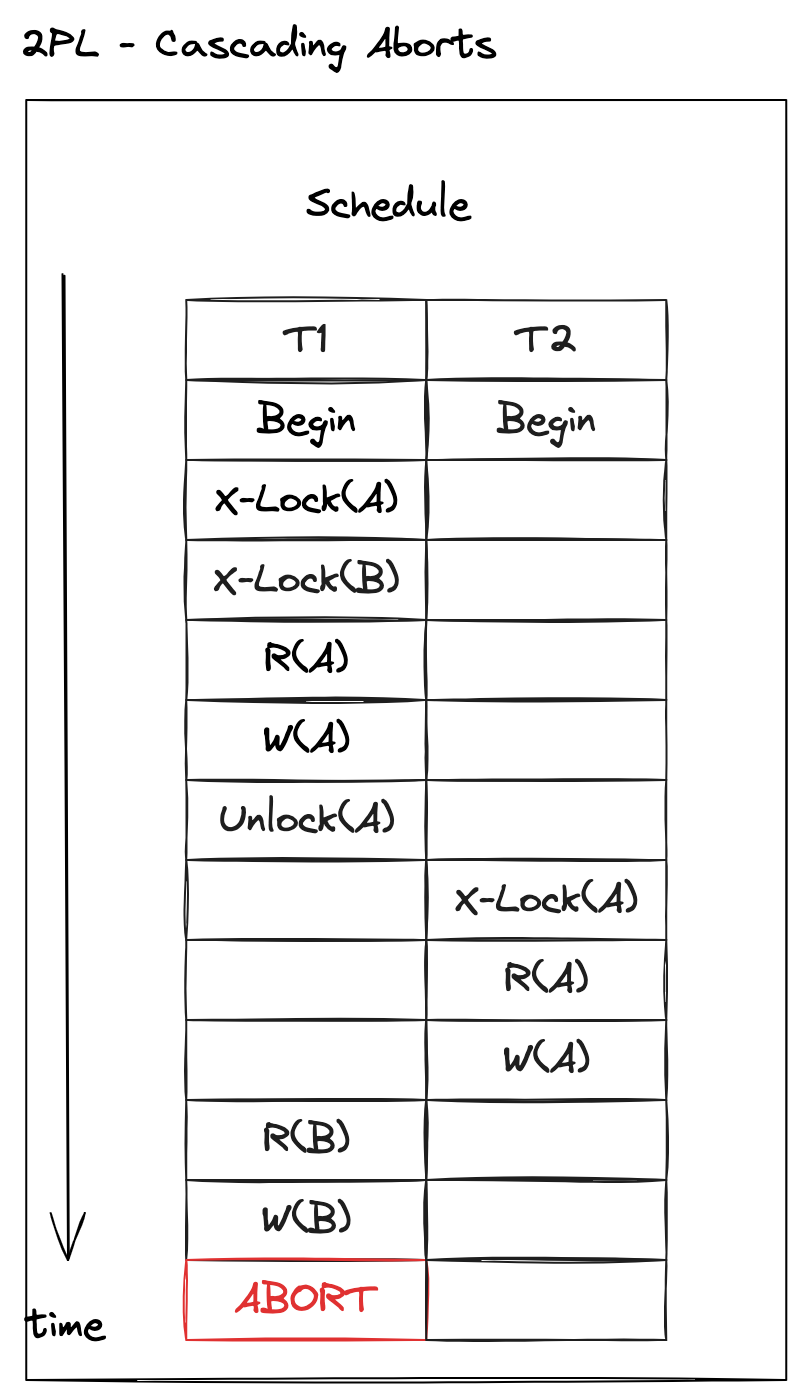
当 T1 未提交而是回滚,如果 T2 不回滚,那么就相当于 T2 读取了 T1 未提交的数据结果,出现脏读。可是,如果要避免这个问题,T2 也只能跟着回滚。这就可能引发级联回滚(cascading aborts),也就是有操作相同数据对象的事务只能跟着回滚。
强严格两阶段锁(Rigorous 2PL, SS2PL)
之所以会出现这样的问题,是 T1 释放锁的时机不好,导致 T2 读取到了 T1 未提交的结果。那么,通过后置锁释放时机,是可以避免上述问题,这就是强严格两阶段锁(Rigorous 2PL, SS2PL)的设计思路:
- 锁增长阶段(Grow):事务会依据操作申请读锁、写锁,这个过程不会释放任何锁。
- 锁释放阶段(Shrink):事务在提交或者回滚之后,释放之前获取的所有锁,同时不能获取新的锁
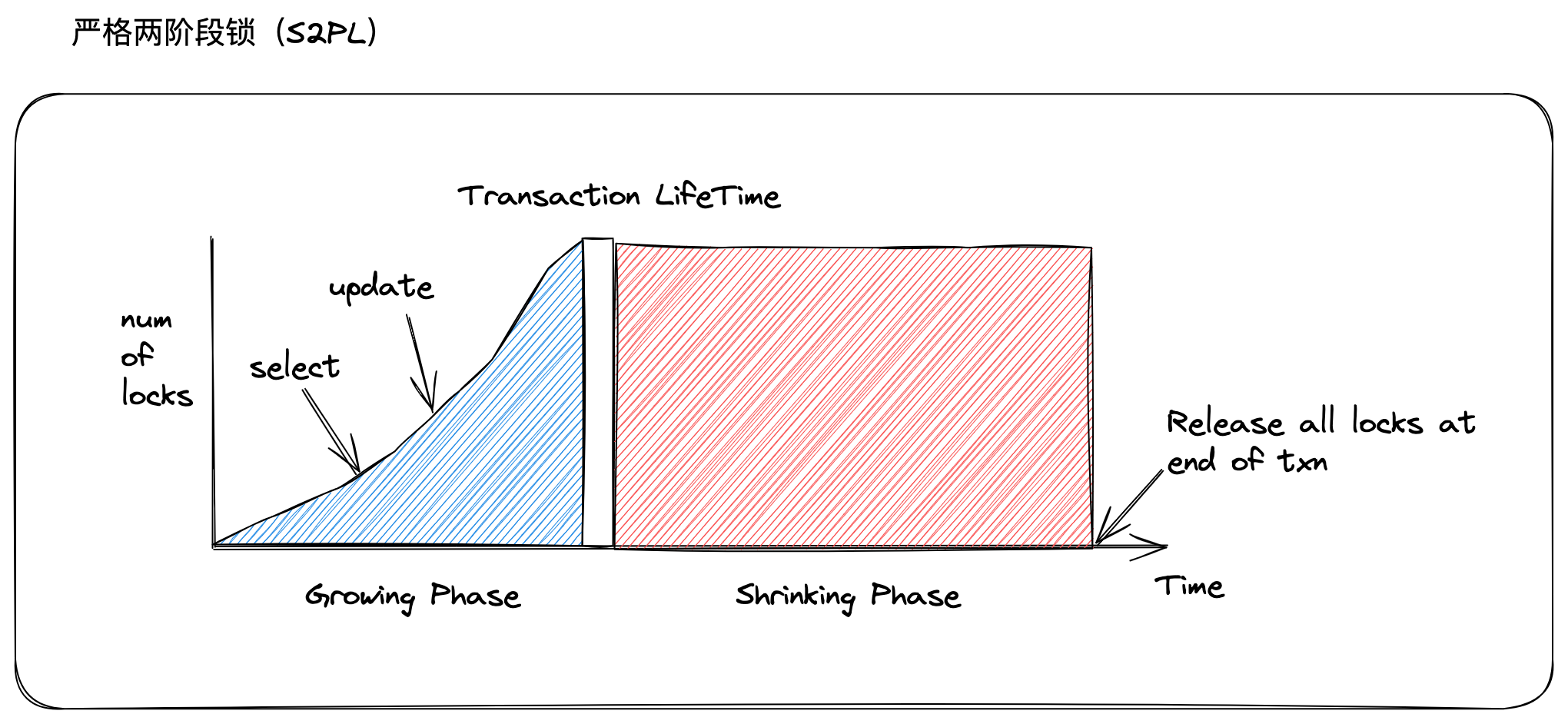
与两阶段锁的区别就在于锁释放时机,强严格两阶段锁是在事务提交或者回滚之后,才会释放。这样,在该事务生命周期内,都会限制别的事务读取到它的执行结果。
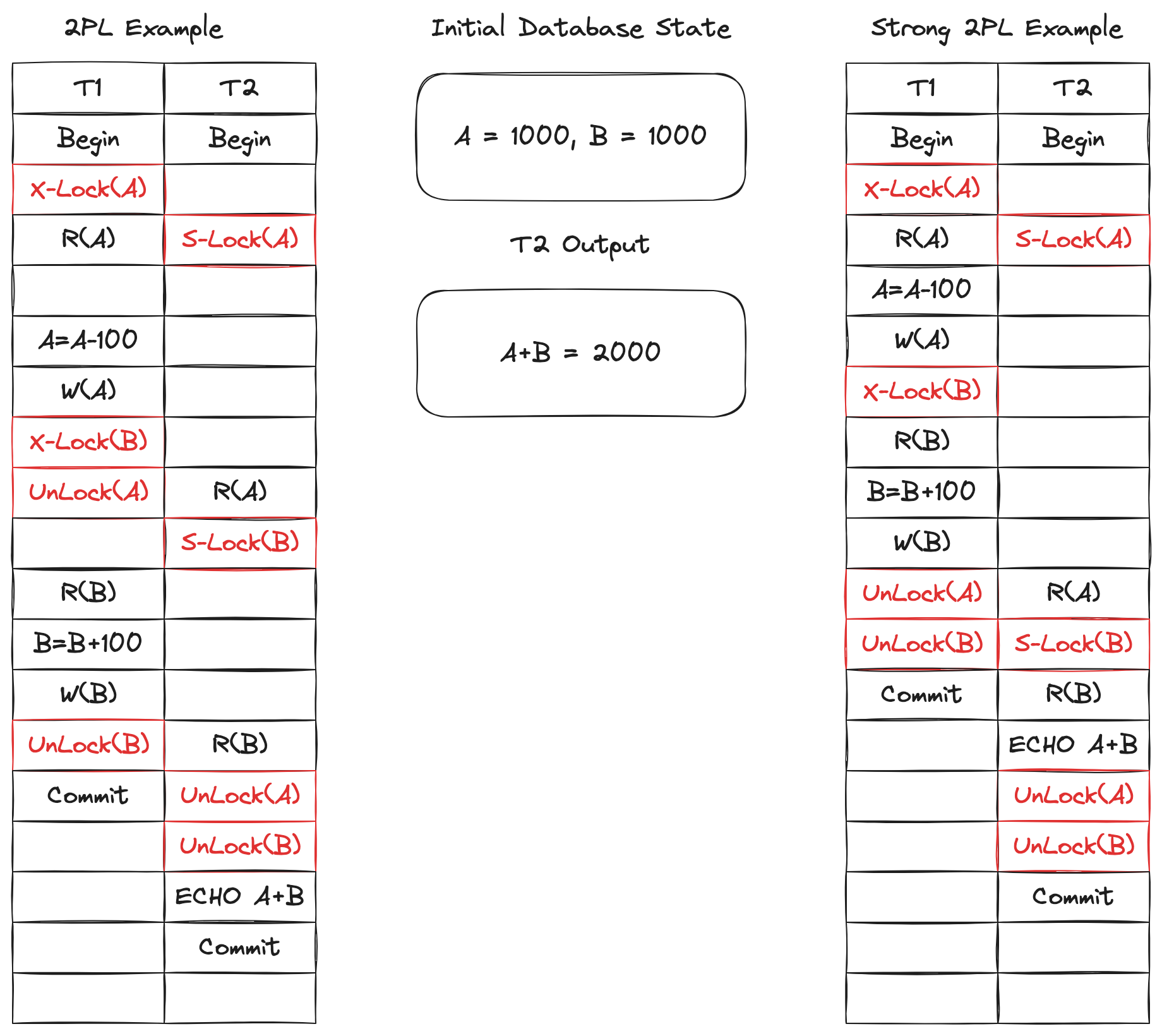
具体实现细节:
- 当一个事务读操作数据对象,那么会请求读锁(共享锁),并且允许其他事务请求读锁。此时如果发现该数据对象上已经有其他事务的写锁,那么必须等待。
- 当一个事务写操作数据对象,那么会请求写锁(排他锁),会阻塞其他事务请求读锁或者写锁。如果该数据对象上已经有其他事务的读锁或者写锁,那么也必须等待。
- 当一个事务先读后写,那就会从读锁升级到写锁。升级过程,就跟上面单独申请写锁一样,该数据对象不能有其他事务的读锁或者写锁。
- 当事务获取到锁,不管是读锁还是写锁,都是在事务结束的时候(提交或者回滚),才会将释放锁。
查看以下例子,注意两阶段锁和强严格两阶段锁的区别:
死锁处理
在使用锁实现事务的串行化调度,会遇到事务相互等待对方释放资源的情况。这就是使用锁的方案,一定会遇到的问题:死锁。
处理死锁主要有两个思路:(1)检测死锁产生后回滚;(2)直接预防死锁出现:
- 基于等待图实现死锁检测(Deadlock Detection)策略
- 死锁预防(Deadlock Prevention)策略
死锁检测(Deadlock Detection)
考虑以下场景:
- T1 读锁 A
- T2 读锁 B
- T3 读锁 C
- T1 写锁 B,等待 T2 释放读锁 B
- T2 写锁 C,等待 T3 释放读锁 C
- T3 写锁 A,等待 T1 释放读锁 A
可以看出,T1,T2,T3 三个事务,他们的等待关系构成了一个环。T1 等待 T2,T2 等待 T3,而 T3 又等待 T1。那么,现在需要设计机制,检测以上死锁的情况。
观察发现,如果能发现事务之间的等待关系出现相互依赖的情况,也就是“环”,那么就说明出现了死锁。这就是等待图(Wait-for Graph)数据结构,所要抽象的关系。
数据库系统会追踪每个事务的获取锁的情况,同时依据以下规则,构建“等待图(Wait-for Graph)”:
- 每个节点代表一个事务
- 如果事务 \(T_i\) 等待事务 \(T_j\) 释放锁资源,就绘制一条从 \(T_i\) 指向 \(T_j\) 的边,记作:“\(T_i \rightarrow T_j\)”
以上示例,所构建出来的等待图如下所示:
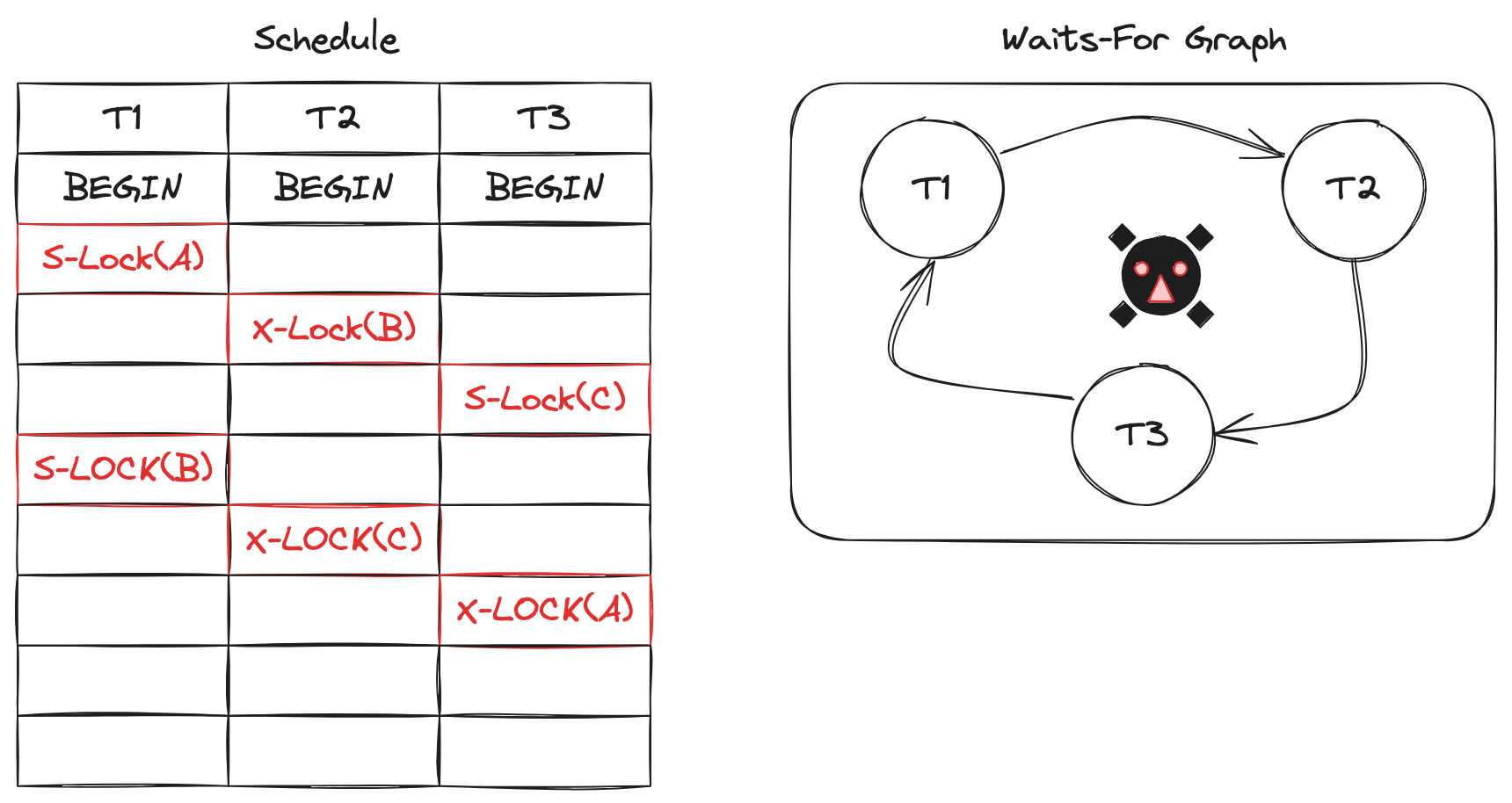
然后,数据库系统会定期检测这张等待图中是否存在“环”,存在的话就说明事务之间存在死锁。当然,还有一些其他细节,比如事务执行结束,它所申请的锁资源释放,那么就需要在图中删除事务所对应的节点和边。
再看另外一个例子,下图所示的三个事务(T1,T2,T3),两个数据对象(A,B)的读写情况,三个事务的操作是逐句提交的,数据库也是逐句执行。
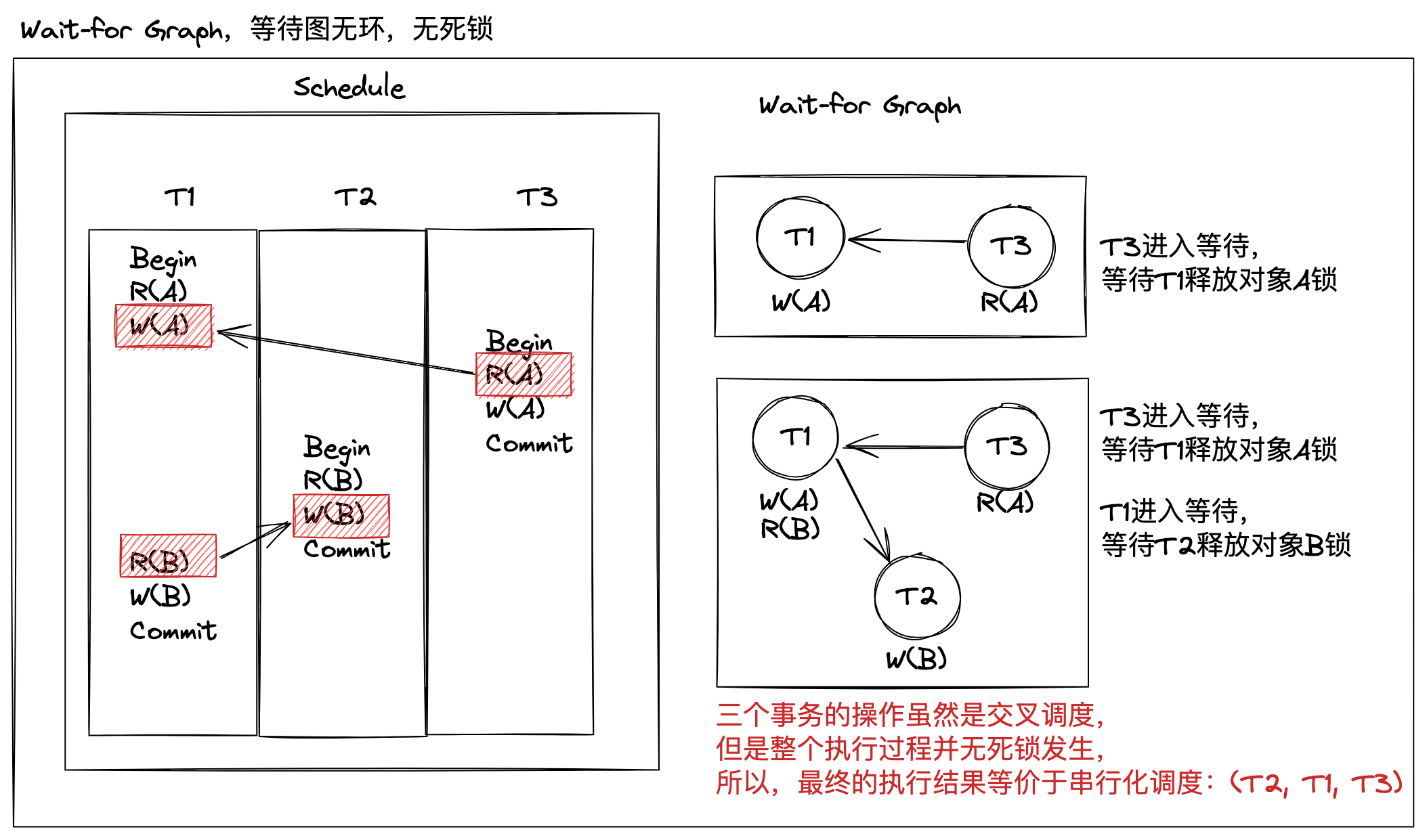
整个过程并无死锁发生,最终的执行结果等价于串行化调度:(T2, T1, T3)。
除了算法实现之外,数据库系统定期检测等待图是否有环的间隔时长设定为多少是合理的,也是需要权衡的:
- 检测等待图会有额外的性能损耗,过于频繁会影响事务执行,影响性能
- 一旦出现死锁事务只能陷入等待,不及时处理会影响客户端的响应时间,同样影响性能
最后,如果真的出现死锁,那么就会处理掉该死锁,确保事务继续执行。一个可行的方案:选择一个事务进行回滚,从而打破死锁。
选择哪一个事务进行回滚,需要综合考虑以下变量来决定:
- 存活时间
- 执行进程(最少/最多,已执行操作数量)
- 已锁住的对象数量
- 需要一并回滚的事务数量
- 已经被重启的次数
回滚被选中事务多少个操作,也有不同的方案:
- 全部回滚
- 最小化回滚(回滚到没有依赖环了,就不回滚)
测试 MySQL 死锁检测机制
数据库表 txn_demo 结构和数据如下所示:
+----+------+
| id | val |
+----+------+
| 1 | 8 |
| 2 | 2 |
| 3 | 10 |
+----+------+
- 将两个会话的隔离级别都设定为 SERIALIZABLE
- T1 先读 id=1,再读 id=2
- T2 先写 id=2,再写 id=1
- 发生死锁,MySQL 杀死 T1 来解除死锁
| T1 | T2 |
|---|---|
| SET SESSION AUTOCOMMIT = OFF; | SET SESSION AUTOCOMMIT = OFF; |
| SET SESSION innodb_lock_wait_timeout = 10; | SET SESSION innodb_lock_wait_timeout = 10; |
| SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; | SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; |
| begin; | begin; |
| select * from txn_demo where id = 1; | update txn_demo set val = val+1 where id = 2; |
| 到这一步还不会有任何问题 | 但是接下来 T1,T2 将获取对方的占用的资源 |
| select * from txn_demo where id = 2; | |
| 此时 T1 陷入等待 | |
| update txn_demo set val = val+1 where id = 1; | |
| 于此同时,T1 被杀死:ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction | T2 执行成功 |
| commit; |
所以, MySQL 有死锁检测机制,并且在发现死锁的同时,就会立马杀死其中一个事务,从而避免死锁等待情况。
死锁预防(Deadlock Prevention)
死锁预防是基于锁实现的串行化调度,解决死锁问题的另外一种方案,实现思路更加简单:当一个事务获取锁资源的时候,发现该资源已经被另外一个事务占用,那么依据策略立马处理不需要依赖异步检测机制。
相比于死锁检测,该方案不需要构建“等待图”,也不需要定期地异步检测是否出现环。
首先,事务启动的时候,数据库系统会为其分配一个时间戳。基于这个初始时间,有两种不同的预防方案:
- Wait-Die(老的可以等待,新的直接杀死)
- 如果【请求锁的事务】,比当前【占用锁的事务】时间更早,那么【请求锁的事务】继续等待 => Wait
- 否则,直接杀死【请求锁的事务】 => Die
- Wound-Wait(老的抢占新的,新的可以等待)
- 如果【请求锁的事务】,比当前【占用锁的事务】时间更早,那么【占用锁的事务】回滚并且释放锁 => Wound
- 否则,【请求锁的事务】等待 => Wait
注意,一个数据库系统只需要实现其中一个方案。不能一会儿用 Wait-Die, 一会儿使用 Wound-Wait。
分析以上两种方案:
Wait-Die 是非抢占式策略。新来的事务如果已经开始执行了,不会被强制终止,老的事务会等待其执行完成(Wait)。当然,会丢弃后续再提交的新事务(Die),从而避免老事务被饿死。比如以下三个事务,分别是: T5,T10,T15。
- 如果 T5 请求的资源被 T10 占用,那么 T5 会等待(T5,Wait)
- 如果 T15 请求的资源被 T10 占用,那么 T15 会被直接杀死 (T15,Die)
与之相反地,Wound-Wait 是抢占式策略。新来的事务哪怕已经在执行了也会被直接杀死(Wound),资源会释放出来给老的事务。当然,再来的新的事务,允许等待老的事务释放资源(Wait)。同样地,还是这三个事务: T5,T10,T15。
- 如果 T5 请求的资源被 T10 占用,那么 T10 会被杀死,也就是说 T5 从 T10 手上抢占走资源 (T10,Wound)
- 如果 T15 请求的资源被 T10 占用,那么 T15 允许等待 (T15, Wait)
不管是哪一个策略,都是优先照顾老的事务,确保它不会被饿死。 Wait-Die 是通过不再执行新的事务来确保老的事务最终能执行到,而 Wound-Wait 更加激进,会直接杀死新的事务来确保老的事务优先执行。
有一个问题需要注意,如果某一事务被杀死后再重启,它的时间戳会更新吗?
答案:并不会,还会保留它原本的时间戳。只有这样,不管是 Wait-Die 或者 Wound-Wait 策略,该事务相对于其他事务最终会是老的事务,那么就会得到执行。如果,每次重启都分配新的时间戳,那么这个事务很大概率会被饿死。
锁粒度(Lock Granularities)
锁管理器的内部结构是一个大的散列表(hash table),虽说查找结果的时间复杂度在理论上是 \(\mathcal{O}(1)\) ,但是从1亿条数据跟1千条数据相比,不管是最终呈现出来的散列表存储结构(重复键处理),还是内存大小的限制,都会导致最后查找的时间复杂度远远高于理论数值。
所以,问题来了。如果某次事务的操作是更新上千万条记录,那么也是记录一千万条锁记录吗?
答案:不是。为了解决锁数量膨胀的问题,引入“锁粒度”的概念。其核心思路,根据场景使用不同“粒度”的锁,从而降低锁管理器需要维护的锁数量。
锁分层结构(Lock Hierarchy)
在数据库系统场景中,自然会想到,按照不同的逻辑单位:库、表、行、属性,来设计锁粒度,也就得到了以下的锁分层结构:
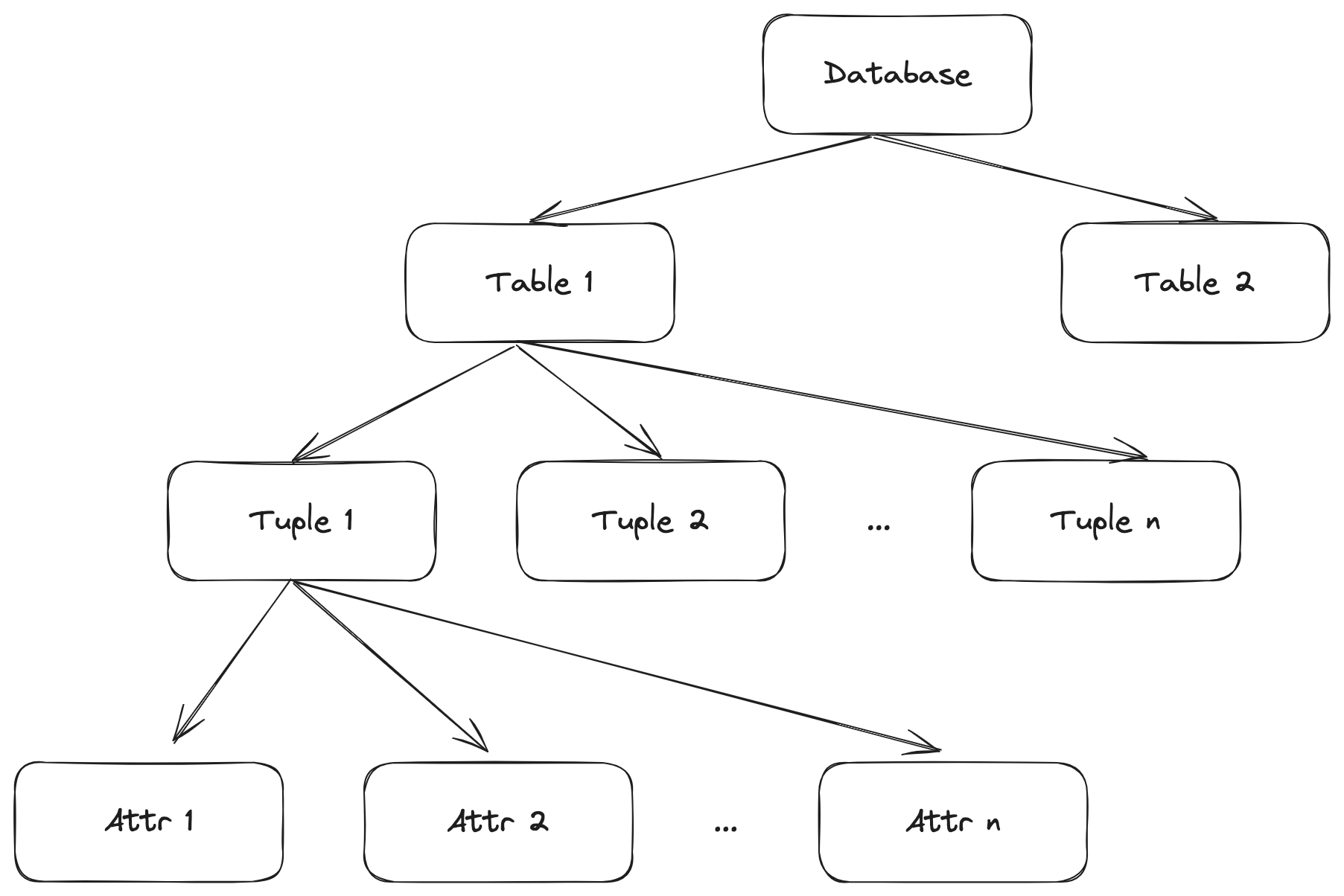
举个例子,比如一次查询出来 1000 行数据要进行更新操作,如果没有 Table 和 Page 粒度的锁,那就得锁 1000 条记录。别的事务事务操作要判断是否跟当前锁资源有冲突,就要和这 1000 条锁记录进行比较。但是如果,这 1000 条记记录刚好在一个“数据页”中,那么完全可以在 Page 粒度上记录一个锁,最终只需要 1 条锁记录就可以,计算和存储成本都会明显减少。
整体思想,就是用一个更大粒度的锁替代更小粒度的锁,在牺牲一定精准度的情况下,提升整体的执行性能。
截至到目前,这个方案存在以下问题。在串行化隔离级别下,考虑以下场景:
- T1 扫描全表,并且更新一部分数据
- T2 读取一条记录
现在只有两种类型的锁:
- 读锁,S-Lock
- 写锁,X-Lock
T1 要从全表中找出符合条件的记录并更新,那么只能在全表加写锁(X-Lock)。虽然 T2 要读取的记录和 T1 要更新的记录集合根本没有交集,可是数据库系统并不知道,所以 T2 只能等待 T1 执行完成,这就加大了 T2 的响应时间,影响了整体性能。
所以,引入锁分层结构后,如果只考虑降低锁数量,就会出现只能在更粗粒度上加锁,假设都在表级别上锁,锁数量是少了,但是并发性能反而是下降。
以上问题关键点,就是在于只有两种锁类型,在更大粒度上粗暴地使用写锁或者读锁,那么依据读写的互斥规则,只能阻塞等待。
为此,在“锁分层结构”的设计之上,又引入“意图锁”的概念。核心思路,增加锁的种类,提高不同锁之间兼容性,在更高层级使用兼容性更高的锁,从而更好地适配不同事务的操作场景,避免了每次只能使用“写锁”去锁全表的情况。
意图锁(Intention Locks)
意图锁,在锁分层结构中,先在更高层级加意图锁,该锁的目地是用于表明该事务在子层级的意图:读或者写。
新增了以下三种锁类型:
- 意图共享锁(IS):表明子层级会上共享锁(S-Lock)
- 意图排他锁(IX):表明子层级会上排他锁(X-Lock)
- 共享+意图排他锁(SIX):
- 当前层级上共享锁(S-Lock),也就意味着该层级下的所有子层级都上共享锁
- 同时,表明子层级节点会上排他锁(X-Lock)
再加上已知的共享锁(S-Lock)和排他锁(X-Lock),这5种锁的兼容性关系,如下表所示:
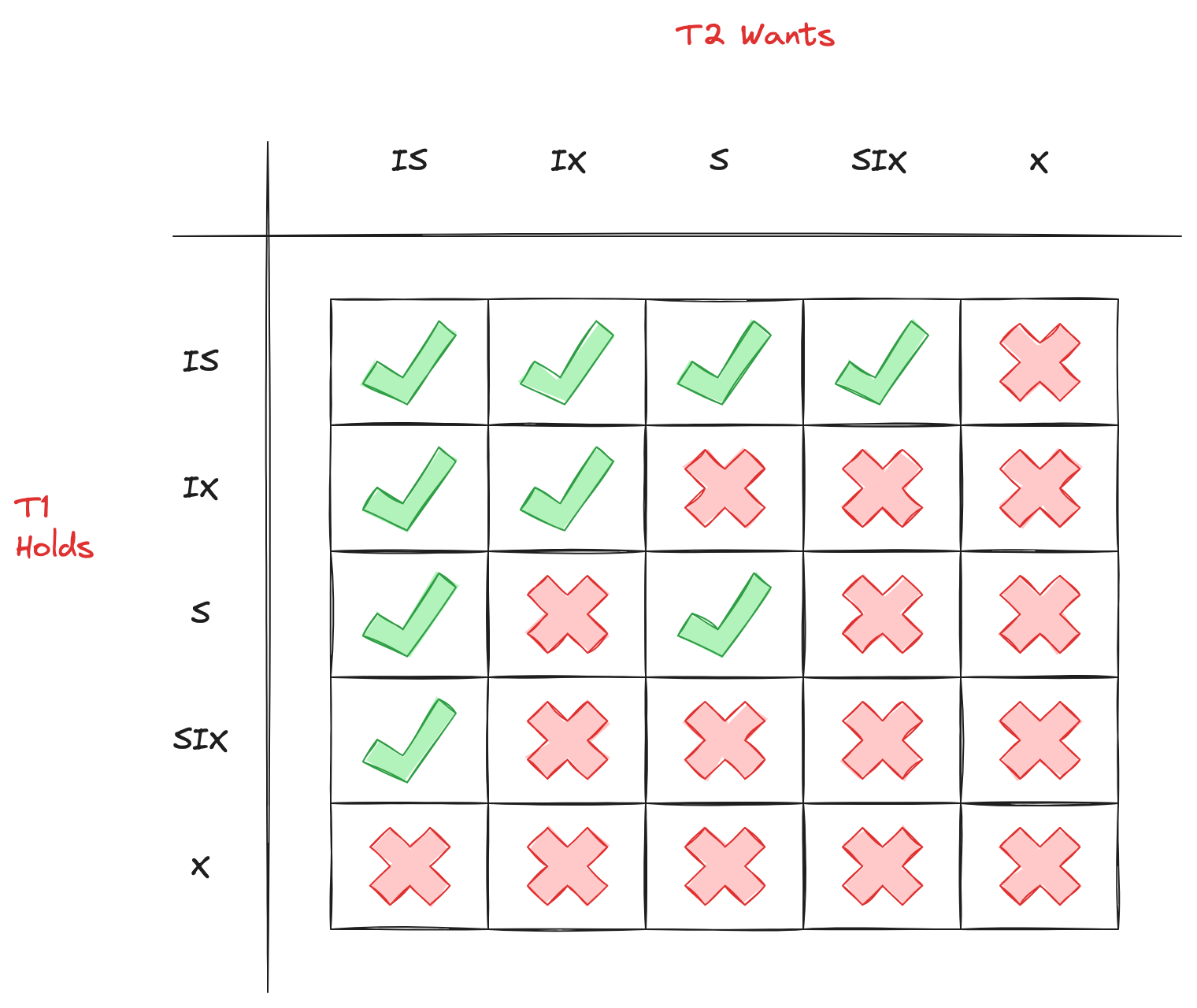
这里分成两个层级来理解,就很好懂了:
- S,X:直接对当前层级及其所有子层级上锁;
- IS,IX:在当前层级上锁,只是表明在子层级要上什么锁的
- SIX:比较特殊,(1)对当前层级及其所有子层级上共享锁(S-Lock);(2)也表明在子层级要上排他锁(X-Lock)
为何 SIX 和 IS 是不互斥?
- “读读共享”,SIX 在当前层级及其所有子层级上共享锁(S-Lock)跟 IS 意图在子层级部分节点上共享锁(S-Lock),并不互斥
- “读写不一定有交集”,SIX 意图在子层级部分节点上排他锁(X-Lock)跟 IS 意图在子层级部分节点上共享锁(S-Lock),不一定有交集,也就是说可能不互斥
- 所以,在当前层级 SIX 和 IS 是不需要互斥,应该交给子层级去判断 S 和 X 是否发生互斥即可
基于锁分层结构和意图锁的上锁协议实现
上锁协议实现:
- 每个事务都要在锁分层结构的最高层级获取合适的锁
- 如果想在子节点获取共享锁(S)或者意图共享锁(IS),那么父节点至少要获取到 IS 级别的锁
- 如果想在子节点获取排他锁(X)、意图排他锁(IX)、共享意图排他锁(SIX),那么父节点至少要获取 IX 级别的锁
简单一句话来说,想要在子层级使用某个锁,至少要在父层级上意图锁。确保在父层级就能告知其他事务,该事务后续要做什么样的操作。
接下来使用,表锁 + 行锁,两层结构来说明上述加锁流程。
第一个例子:
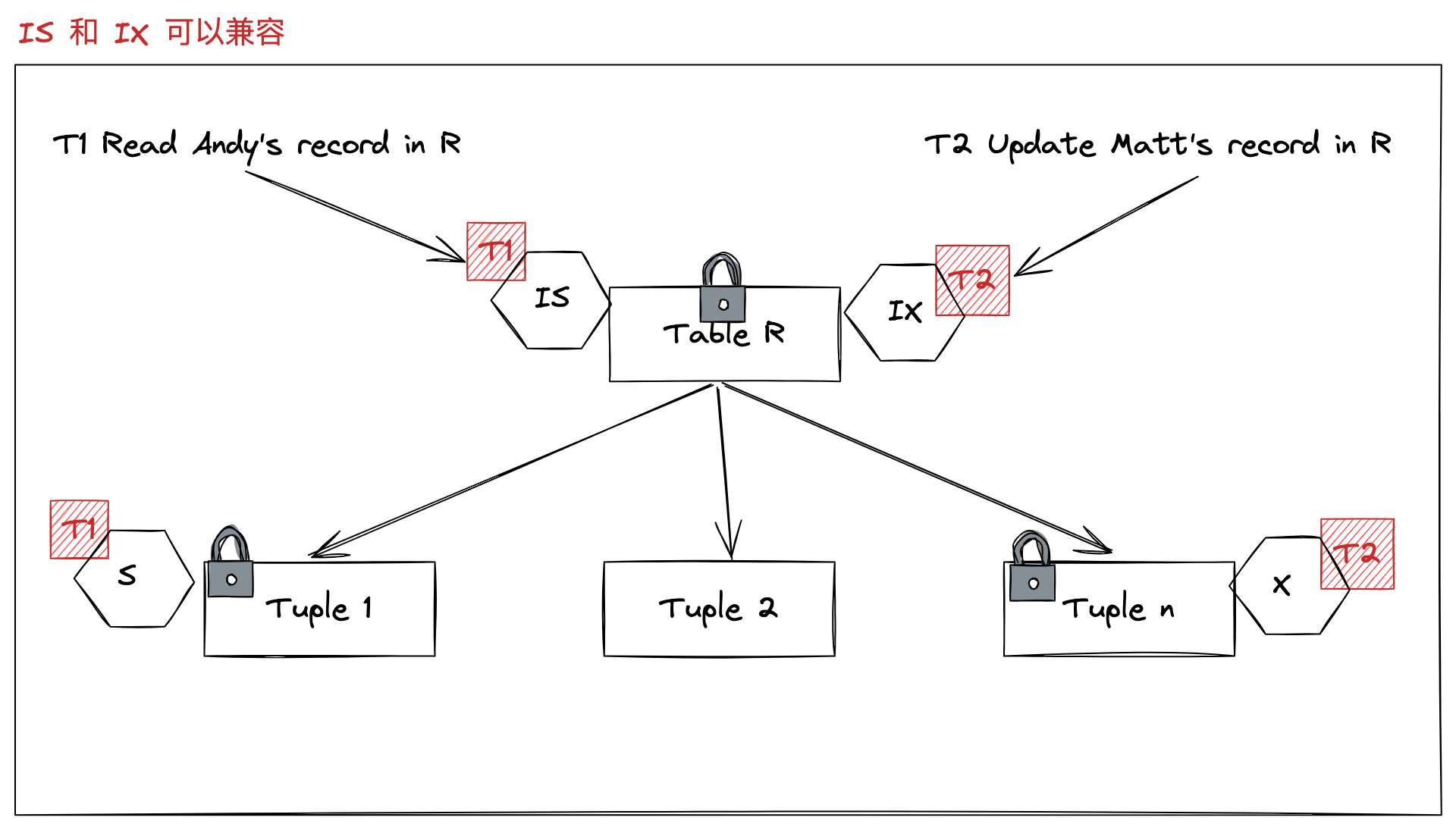
- 事务 T1 读取一条账户记录。表级别就要加上 IS,表明行级别意图读
- 事务 T2 更新一条账户记录。表级别就要加上 IX,表明行级别意图写
- 从表级别来看,T1 意图读,T2 意图写,但是在这个层级并不知道两个事务会不会操作同一个行,那么就没有必要去限制 T2 事务,可以把这个问题交给行级别去判断。
再看一个例子:
- 事务 T1 扫全表并且更新一部分数据,使用 SIX。在“表”层级上共享锁然后“行”层级部分数据会上排他锁
- 事务 T2 读取一条记录,使用 IS。在“行”级别部分数据会上要共享锁
- 跟事务 T1 “表”层级共享锁,并不互斥。
- 跟事务 T1 “行”层级排他锁是否互斥,此时并不知道。
- 所以,在“表”层级判断的时候,两个事务并不互斥,允许事务 T2 执行
- 事务 T3 扫描全表 使用 S。在“表”层级直接上共享锁
- 肯定跟事务 T1 “行”层级排他锁互斥。事务 T3 没必要再请求“行”层级锁资源,可以在“表”层级就做出判断,肯定互斥,拒绝事务 T3 执行
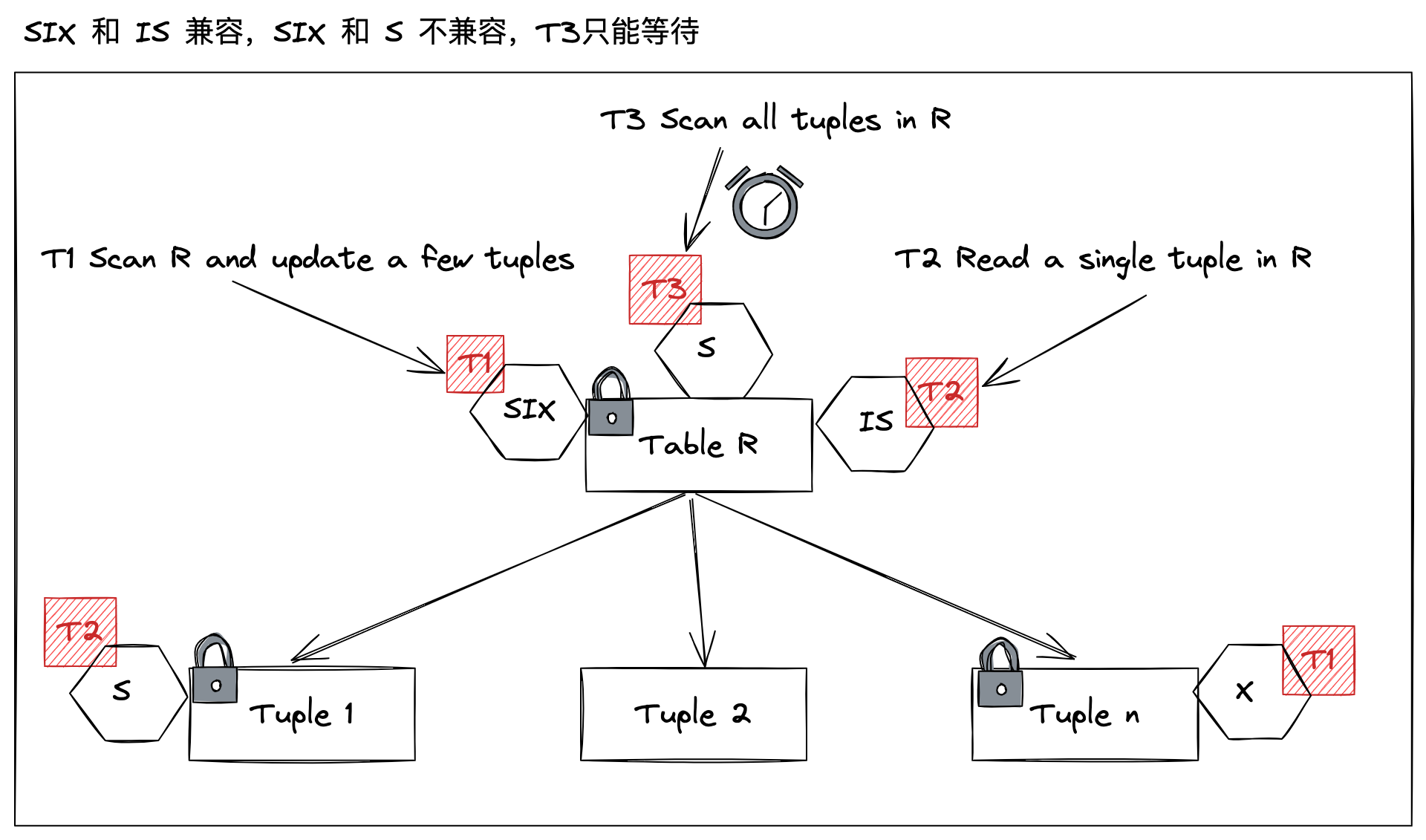
第二个例子,可以看出该设计方案很好地平衡了并发执行和锁数量:
- 事务 T2,不会在“表”层级就被阻塞,允许并发执行;
- 事务 T3,不需要获取大量“行”层级锁,才发现存在互斥,降低锁数量;
分级锁结构+意图锁的设计方案,在实践中非常有用,数据库系统只需要给事务分配少量的锁,就能判断事务能否并发执行。
总结
本篇从两阶段锁(2PL)出发,介绍该方案为何能被称为两阶段,之后为了解决级联回滚问题,又引入了强严格两阶段锁(Rigorous 2PL, SS2PL)。两者区别在于,后者只在事务提交或者回滚的时候,释放锁。然而,基于锁的实现方案,必然会有死锁问题。为此,介绍了两种解决方案:(1)基于等待图的死锁检测回滚;(2)死锁预防。其中,死锁检测,需要数据库系统构建依赖图,并定期地检测图中是否有环,从判断事务之间是否存在死锁。如果有环,就挑选一个事务进行回滚。而,死锁预防,不像死锁检测,还要异步地定期检测,它是当场判断当场处理,不管是非抢占式的 Wait-Die 方案,还是抢占式的 Wound-Wait 方案,都是优先照顾老的事务,避免老的事务被饿死。最后,为了解决锁数量膨胀,同时又兼顾并发性能,引入了锁分层结构+意图锁的设计方案,数据库系统只需要给事务分配少量的锁,就能判断事务能否并发执行,进一步提升性能。
参考文献
- CMU 15-445 Fall 2019 17 Two-Phase Locking Concurrency Control 12:03 ~ 1:04:08
- Designing Data-Intensive Applications 07 Transactions P258
- What is the difference between “wait-die” and “wound-wait” deadlock prevention algorithms?