浅谈乐观并发控制协议
介绍乐观并发控制协议核心思路、实现方法以及该协议所具备的特性。
关键词:乐观并发控制协议、冲突可串行化、时间戳顺序、后向验证、前向验证
乐观并发控制协议(Optimistic Concurrency Control,OCC)
乐观并发控制协议和基本时间戳顺序协议同样是:(1)基于时间戳顺序;(2)并归属于乐观并发控制协议这一大类。
该协议基本思想,将事务拆分成三个阶段,并在不同阶段完成以下工作:
- 读取阶段(Read Phase):追踪事务会用到的读数据集合和写数据集合都拷贝到私有工作空间(private workspace),在该阶段的数据操作都是先应用在该工作空间
- 验证阶段(Validate Phase):当事务提交的时候,验证它的数据集合是否和其他事务的数据集合冲突
- 写入阶段(Write Phase):验证通过可以将私有工作空间的数据应用到数据库系统全局数据,否则终止事务并重启它
查看以下示例,对该协议执行流程有个初步理解:
- 事务 T1 在读取阶段(Read Phase)将需要的数据对象拷贝到各自的私有工作空间
- 事务 T1 写入操作,更改的是私有的工作空间的数据对象
- 事务 T1 进入验证阶段(Validate Phase),按照进入验证阶段的顺序,此时 TS(T1) = 2
- 按照验证规则条件(2),事务 T2 在事务 T1 开始写入阶段之前完成写入阶段,那么就验证事务 T2 的写数据集合跟事务 T1 的读数据集合是否有交集。因为事务 T2 没有任何写入操作,所以一定是空集
- 验证通过,更新 W-TS = 2
- 事务 T1 验证通过后,进入写入阶段(Write Phase),将私有的工作空间的改动应用到数据库系统全局数据并持久化
乐观并发控制协议验证阶段实现逻辑
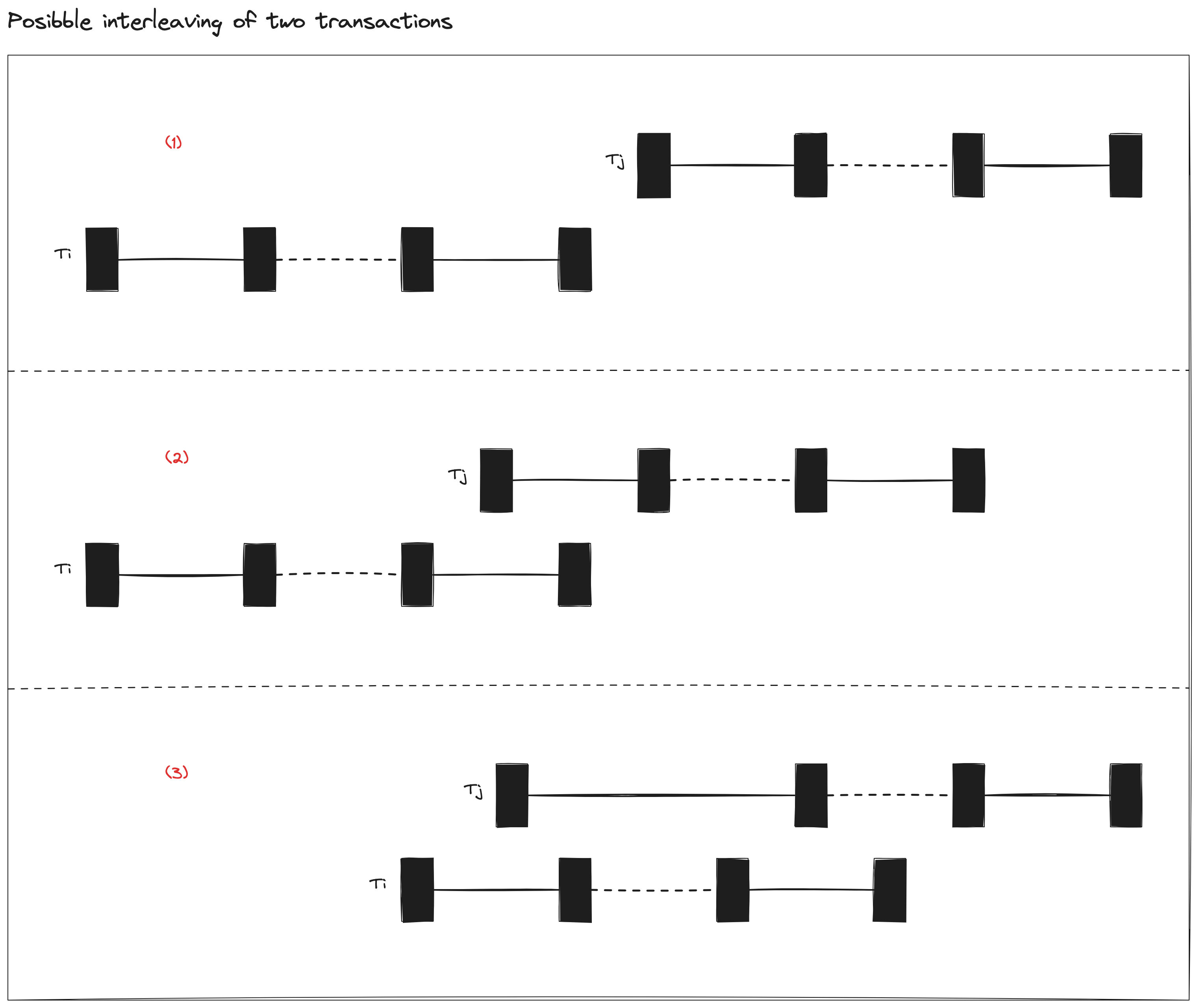
乐观并发控制协议的验证阶段基本思路,就是检查提交的事务跟其他事务是否存在读写冲突,并确保这些冲突操作只有一个执行顺序,也就是从老的事务指向新的事务,如果进入验证阶段的时间戳是 \(TS(T_i) \lt TS(T_j)\),则串行化顺序是 \(T_i \rightarrow T_j\) 。
为保证上述串行化顺序,任一个事务 \(T_j\) 其时间戳为 t(j),对于所有 t(i) < t(j) 的事务 \(T_i\),\(T_j\) 必须满足以下三个条件之一:
条件(1),\(T_i\) 在 \(T_j\) 开始读取阶段之前完成写入阶段,如下图(1)所示:
两个事务的阶段没有任何重合,不会有任何冲突,也就不需要做额外判断
条件(2),\(T_i\) 写数据集合跟 \(T_j\) 读数据集合没有交集,并且 \(T_i\) 在 \(T_j\) 开始写入阶段之前完成写入阶段,如下图 (2) 所示:
- 因为 \(T_i\) 在 \(T_j\) 开始写入阶段之前就已经完成写入阶段,那么 \(T_j\) 的写入对 \(T_i\) 来说是完全不可见的,也就是说,不会影响 \(T_i\) 一开始读取阶段的结果,时序上已经确认不会有 “写(\(T_j\))-写(\(T_i\))冲突” 和 “写(\(T_j\))-读(\(T_i\))冲突”
- 剩下地,\(T_j\) 的读数据集合跟 \(T_i\) 的写数据集合没有交集,即不会有“读(\(T_j\))-写(\(T_i\))冲突”
- 结论:满足条件(2),即可避免三种类型的冲突,\(T_j\) 可以提交并写入结果
条件(3),\(T_i\) 的写数据集合跟 \(T_j\) 的读数据集合或者写数据集合都没有交集,并且 \(T_i\) 在 \(T_j\) 完成读取阶段之前完成自己的读取阶段,如下图 (3) 所示:
- 相比于条件(2),该条件并不要求 \(T_i\) 在 \(T_j\) 开始写入阶段之前完成写入阶段。所以,得分两种情况来看待:
- \(T_i\) 在 \(T_j\) 开始写入阶段之前完成写入阶段,那么会进入到条件(2)的判断
- \(T_i\) 在 \(T_j\) 开始写入阶段的时候,尚未完成写入阶段。也就是说,当 \(T_j\) 开始写入阶段的时候,实际上有一批并发事务完成读取阶段正处于写入阶段。那就要求,\(T_i\) 写入不会影响 \(T_j\) 的读取和写入,所以要求 \(T_i\) 的写数据集合跟 \(T_j\) 的读数据集合或者写数据集合都没有交集,这样就避免了 “读(\(T_j\))-写(\(T_i\))冲突”以及 “写(\(T_j\))-写(\(T_i\))冲突”
- 最后,反过来看,\(T_j\) 进入写入阶段之前,\(T_i\) 已经进入写入阶段了,从时序上 \(T_j\) 的写入就不可能影响 \(T_i\) 读取结果,即不会有 “写(\(T_j\))-读(\(T_i\))冲突”
- 结论:满足条件(3),同样可以避免三种类型的冲突,\(T_j\) 可以提交并写入结果
实现逻辑如下所示(伪代码):
// 事务开启
tbegin = (
create set := empty
read set := empty
write set := empty
delete set := empty
start tn := tnc
)
// 事务读取阶段
...
// 事务“验证-写入”阶段
tend = (
<finish tn := tnc;
finish active := (make a copy of active);
active := active U {id of this transaction}>;
valid := true;
// 条件(2)
for t from start tn + 1 to finish tn do
if (write set of transaction with transaction number t intersects read set)
then valid := false;
// 条件(3)
for i in finish active do
if (write set of transaction T_i intersects read set or write set)
then valid := false;
if valid
then (
(write phase);
<tnc := tnc + 1;
tn := tnc;
active := active - {id of this transaction}>;
(cleanup))
else (
<active := active - {id of this transaction}>;
(backup))
)
- 初始化(tbegin):
- 读、写数据集合都是空集
- 事务启动,记录开始时间戳,记作:
start tn
- 期间,事务读取阶段,会记录读、写数据集合;
- 进入“验证-写入”阶段(tend):
- 1)记录“先于事务 \(T_j\) 完成读取阶段正在写入阶段”的事务集合,接下来是一组原子性操作:
finish tn := tnc:记录事务进入验证阶段的时间戳finishi active := (make a copy of active):拷贝“先于事务 \(T_j\) 完成读取阶段正在写入阶段”的事务集合,会用在条件(3)active := active U {id of this transaction}>:同时将 \(T_j\) 添加到“已完成读取阶段正在写入阶段”的事务集合中
- 2)接下来,开始实现条件(2)
for t from start tn + 1 to finish tn do:对所有在事务 \(T_j\) 开始写入阶段之前已经完成写入阶段的事务 \(T_i\),都要做以下判断:if(write set of transaction with transaction number t intersects read set):\(T_i\) 的写数据集合是否跟 \(T_j\) 的读数据集合有交集then valid := false:如果有,就标记验证失败
- 3)紧接着,就是实现条件(3)
for in in finish active do:在 \(T_j\) 进入写入阶段的同时,对于任何“先于事务 \(T_j\) 完成读取阶段正在写入阶段”的事务,都要做以下判断:if (write set of transaction T_i intersects read set or write set):事务 \(T_i\) 的写数据集合跟 \(T_j\) 的写数据集合以及读数据集合都没有交集then valid := false:如果有,就标记验证失败
- 4)验证通过,就要开始执行写入阶段
write phase:要注意并不是加锁保护区域,这里允许并发写入数据库系统的全局数据- 累加全局时间戳 tnc 同时设定事务id,这是一组原子性操作:
tnc := tnc + 1:表明最新已提交的事务编号已经到了tnc + 1- (a) 对应到事务启动的时间戳
start tn := tnc,意味着新来的事务可以拿到一个时间戳 - (b) 对应到事务“验证-写入”阶段:
finish tn := tnc,意味着事务进入验证阶段的时候的时间戳 - 依赖事务提交成功后,不断累加的
tnc就可以界定时间戳范围,每个事务执行读取阶段期间,有哪些事务已经验证通过并已提交
- (a) 对应到事务启动的时间戳
tn := tnc:每一个事务在写入成功的时候,才会记录递增后的事务编号active - {id of this transaction}从 active 中剔除掉,写入成功的,自然要从“正在写入阶段”的active集合中提出掉了
- 5) 验证不通过,回滚
active - {id of this transaction}从 active 中剔除掉,回滚事务,同样地要从“正在写入阶段”的active集合中提出掉了
- 1)记录“先于事务 \(T_j\) 完成读取阶段正在写入阶段”的事务集合,接下来是一组原子性操作:
总结乐观并发控制协议的验证阶段的实现,当一个事务提交的时候只需要关心两种事务集合,:(1)从事务开启到进入验证阶段期间已经写入的事务集合(start tn + 1 ~ finish tn);(2)先于事务 \(T_j\) 完成读取阶段正在写入阶段的事务集合(finish active)。对于第(1)种,由于这部分事务已经写入,那么就要避免这部分事务写入影响到了正在提交事务的读取结果,所以要求 \(T_i\) 的写数据集合跟当前事务 \(T_j\) 的读数据集合没有交集;对于第(2)种,由于这部分事务正在写入,需要额外要求 \(T_i\) 的写数据集合跟当前事务 \(T_j\) 的写数据集合没有交集,如果不判断这个条件,等到写入阶段(write phase),并不是互斥操作就会出现不同事务混合写入结果,从而破坏一致性。
乐观并发控制协议,最终得到的同样是冲突可串行化的调度系列。回忆下在冲突可串行化的判断方法:构建依赖图,当存在冲突操作的时候,就绘制一条边线,从老的事务指向新的事务。乐观并发控制协议能保证冲突操作都是从老的事务指向新的事务,也就是说,整个依赖图不存在环,因此最终能得到就是一个冲突可串行化的调度序列,并且该串行化调度序列就是:\(T_i \rightarrow T_j\)。
乐观并发控制协议验证方式简化:后向验证(Backward Oriented Validation,BOCC)
后向验证(Barckward Oriented Validation)是 Härder 针对首次发布的 OCC 重新归纳整理,将条件(2)和条件(3)合并之后并作出简化::
\(T_i\) 写数据集合跟 \(T_j\) 读数据集合没有交集,并且 \(T_i\) 在 \(T_j\) 完成读取阶段之前完成自己的读取阶段。
具体实现逻辑,在事务 \(T_j\) 启动的时候记录时间戳 \(T_{start}\),在事务进入验证阶段的时候记录时间戳 \(T_{finish}\)。对于这期间,已经完成读取阶段的事务 \(T_i\) ,都判断事务 \(T_j\) 的读数据集合跟 \(T_i\) 的写数据集合没有交集。如果验证通过,则事务 \(T_j\) 提交,否则就回滚。
伪代码如下所示:
VALID := TRUE;
FOR Ti := T{start+1} TO T{finish} DO
IF Tj 读数据集合跟 Ti 写数据集合的交集不是空集 THEN
VALID := FALSE
IF VALID THEN COMMIT
ELSE ABORT;
查看以下示例:
当事务 \(T_j\) 进入验证阶段的时候,需要判断 \(T_j\) 的读数据集合跟事务 \(T_2\) 和 \(T_3\) 的写数据集合是否有交集。因为只有这两个事务,在事务 \(T_j\) 开始执行到进入验证阶段期间,完成了读取阶段。
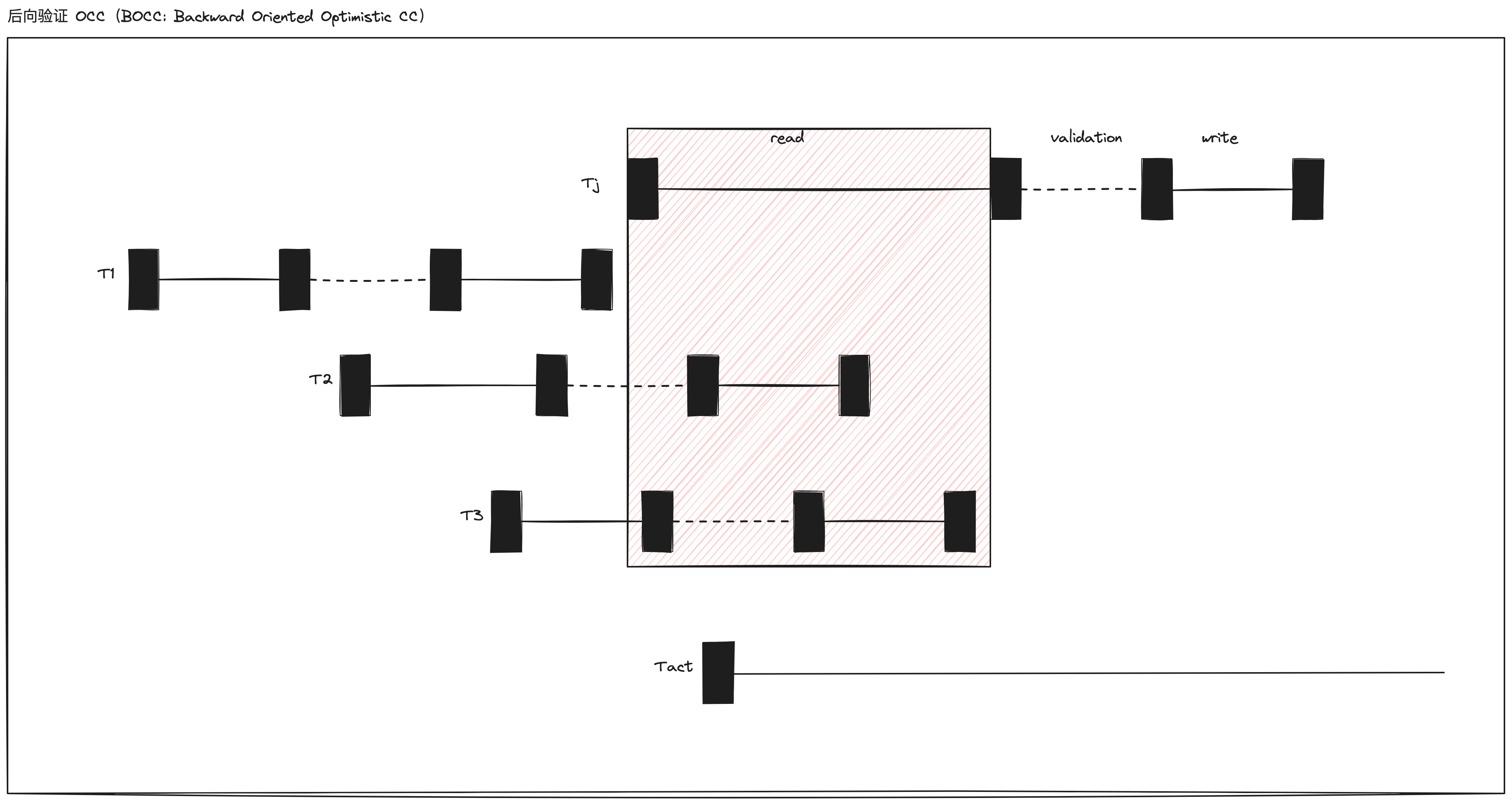
上述给定的验证过程,只允许一次验证(validating)和提交(committing)一个事务。这个过程必须在“临界区(critical section)”内执行,并跟其他打算提交的事务进行判断。
相比于传统 OCC 的条件(2)、条件(3),这里为什么不需要判断事务 \(T_j\) 的写数据集合和事务 \(T_i\) 的写数据集合是否有交集?
因为限制验证阶段判定过程是“临界区”,每次只能有一个事务正在验证和提交。等事务 \(T_j\) 验证的时候,在它之前完成事务都已经提交了。那么事务 \(T_j\) 提交的改动,哪怕跟事务 \(T_i\) 的写数据集合有交集,也属于符合预期的串行化更新,哪怕有交集也并不会影响结果正确性。
BOCC 存在的问题:(1)哪怕是只读事务也需要验证;(2)需要维护重叠部分的事务的写数据集合直到这一批阶段存在重叠的最后一个并发事务提交,才能释放写数据集合,这就会带来额外的内存开销。
乐观并发控制协议验证方式改进:前向验证(Forward Oriented Validation)
FOCC 其验证阶段只检查当前事务的写数据集合是否跟活跃事务(正在读取阶段的事务)的读数据集合是否存在交集。相比于 BOCC , FOCC 并不需要验证只读事务,只读事务在事务结束的时候(EOT)可以直接提交。
\(T_i\) 读数据集合跟 \(T_j\) 的写数据集合没有交集,并且 \(T_i\) 在 \(T_j\) 进入验证阶段的时候正处于读取阶段。
具体实现逻辑:当事务 \(T_j\) 进入验证阶段的时候,对所有此时尚未完成读取阶段的事务 \(T_i\),都判断其读数据集合跟事务 \(T_j\) 的写数据集合有没有交集。没有交集,那么事务 \(T_j\) 就可以应用它的写入结果。
VALID := TRUE;
FOR Ti := T{act1} TO T{actn} DO
IF Tj 写数据集合跟 Ti 读数据集合的交集不是空集 THEN
VALID := FALSE
IF VALID THEN COMMIT
ELSE RESOLVE CONFLICT;
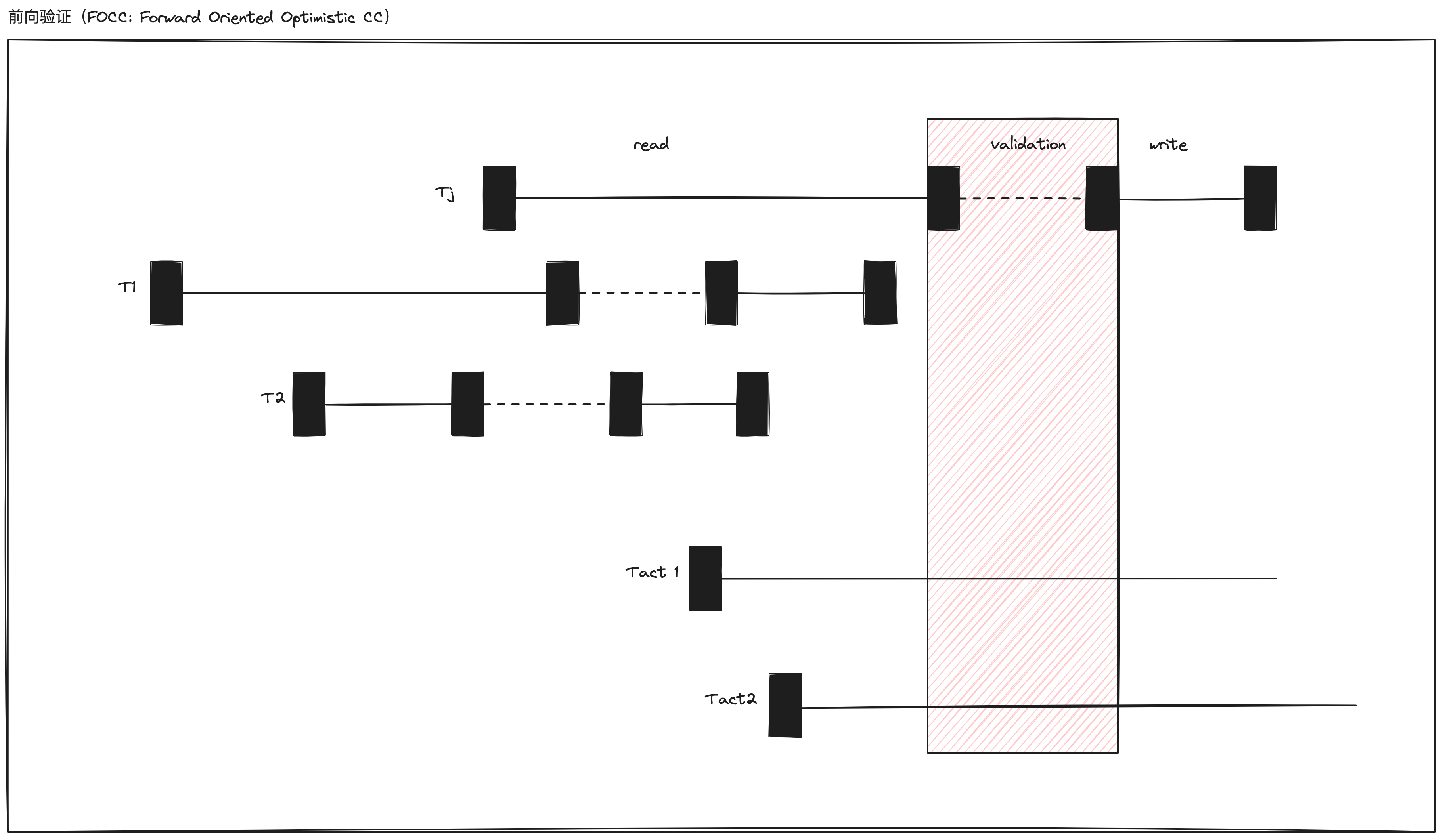
查看以下示例:
当事务 \(T_j\) 进入验证阶段的时候,需要判断 \(T_j\) 的写数据集合跟事务 \(T_{act1}\) 和 \(T_{act2}\) 的读数据集合是否有交集。因为只有这两个事务,在事务 \(T_j\) 进入验证阶段的时候,正处于读取阶段。与 BOCC 一样,FOCC 的验证阶段,同样要在“临界区(critical section)”内执行。
总结
乐观并发控制协议,基于这样的假设,一个数据库系统中有很多数据的时候,不同事务更新的数据几乎没有重合,那么一开始上锁实际上就是在浪费性能且无必要。所以,相比于上锁方案,比如强严格两阶段锁(SS2PL),该协议:
- 没有上锁的开销
- 不需要处理死锁问题
- 冲突较少的时候会有较好的性能
但实际情况并不会这么简单:
- 事务有被饿死的风险,特别是对于长写事务(long writer),容易跟其他事务有数据交集,那么就可能不断被要求回滚
- 拷贝数据到私有工作空间是有性能开销
- “验证-写入阶段”会上“闩锁(latch)”确保互斥,而且每个事务提交的时候都要做冲突检测,如果并发较大地情况,不管有没有冲突这部分检测都是无法避免,这会影响性能
- 最后,相比于上锁协议是在事务执行期间对某一个数据对象操作就上锁阻塞,乐观并发控制协议是在读取阶段全部完成之后,进入验证阶段才会检测是否存在冲突,此时冲突了再回滚会浪费更多机器性能