使用 Golang Colly 工具包爬取 English Pod 对话文本
简单介绍 Golang Colly 工具包的用法,特别地,详细分析框架是如何实现一个刮削器处理 HTML 页面。有了这部分基础知识之后,会实现一个示例,爬取 English Pod 归档网站生成365份对话文本文件。
关键词:网络爬虫、Colly、English Pod
Golang Colly 简单介绍
Colly 是一个 Golang 工具包,可同时实现网络爬虫(Web Crawling)和网络刮削器(Web Scraping)。它基于 net/http 提供简洁 API 实现 HTTP 请求,以及封装 goquery 工具包提供解析 HTML/XML 页面提取所需内容的能力。
一个官网上的简单例子:
func main() {
// 1.初始化一个收集器
c := colly.NewCollector()
// 2.定义一个解析方法,找到页面上所有 a 标签,并访问
c.OnHTML("a", func(e *colly.HTMLElement) {
e.Request.Visit(e.Attr("href"))
})
// 3.发起请求之前,打印 url
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
// 4.启动点
c.Visit("http://go-colly.org/")
}
首先,初始化一个收集器(Collector)。收集器是 Colly 的核心类,主要负责:(1)发起网络请求拉取内容;(2)提供可配置化的参数,快速定制化不同场景的爬虫工具;(3)并且支持挂载不同的回调方法处理节点。
接下来,挂载了两个回调方法:OnHTML 、OnRequest:
- OnHTML 返回结果是 HTML 格式的时候触发,而
"a"就是类似jQuery所提供的选择器语法,这里表示的是所有 a 标签 - OnRequest 是在每次发起请求之前触发,这里是打印下访问的链接地址
最后,启动收集器。通过 Visit 方法,传入一个启动页面的地址。
整个例子的效果就是从 http://go-colly.org/ 地址开始,抓取到每一个 a 标签的地址(href),并继续访问,期间每次发起请求前打印下链接。
Colly 一共有6种回调方法,如下所示:
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
c.OnError(func(_ *colly.Response, err error) {
log.Println("Something went wrong:", err)
})
c.OnResponse(func(r *colly.Response) {
fmt.Println("Visited", r.Request.URL)
})
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
e.Request.Visit(e.Attr("href"))
})
c.OnXML("//h1", func(e *colly.XMLElement) {
fmt.Println(e.Text)
})
c.OnScraped(func(r *colly.Response) {
fmt.Println("Finished", r.Request.URL)
})
它们的调用时序是:
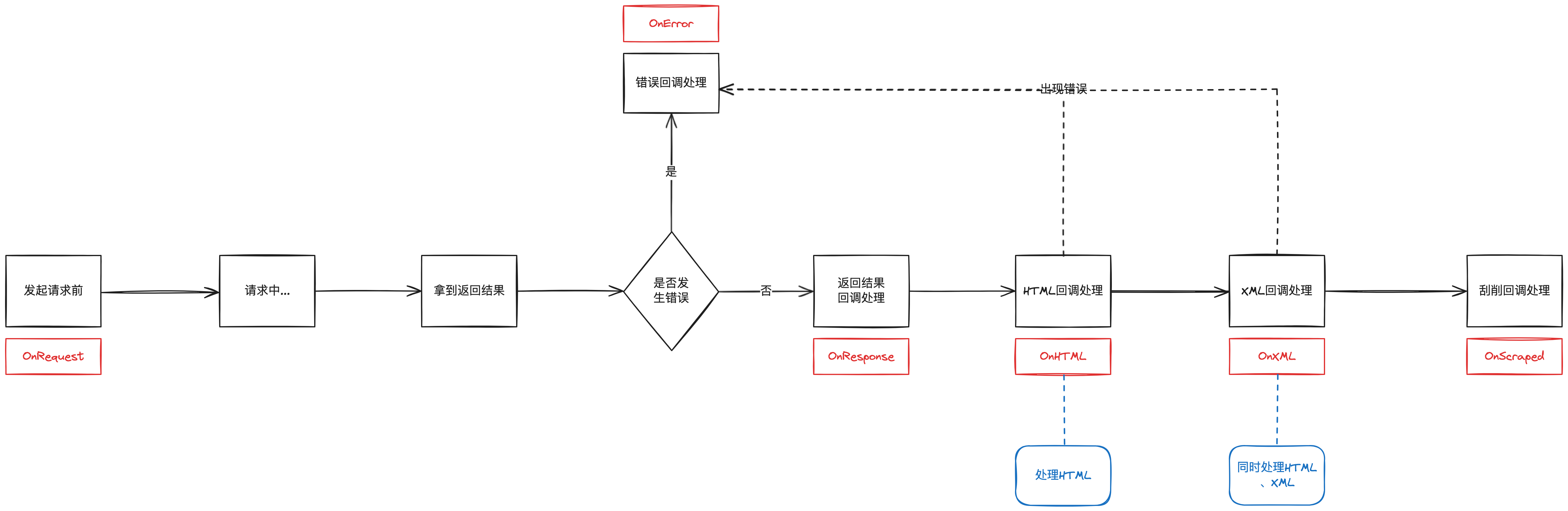
处理 HTML 页面流程
爬取网页内容的时候,初始化一个收集器(Collector)之后,通常会调用 c.OnHTML 方法,注册一个处理 HTML 元素的回调方法:
c.OnHTML("a.stealth.download-pill[href*=html]", func(e *colly.HTMLElement) {
contentCollector.Visit(e.Request.AbsoluteURL(e.Attr("href")))
})
"a.stealth.download-pill[href*=html]"是元素选择器,语法类似 JQuery 选择器func(e *colly.HTMLElement) {}就是回调方法
这个方法的作用就是,当收集器爬取到一个 HTML 页面,该页面中有命中 "a.stealth.download-pill[href*=html]" 选择器的元素,就会调用回调方法。
Collector.OnHTML 具体实现如下:
// OnHTML registers a function. Function will be executed on every HTML
// element matched by the GoQuery Selector parameter.
// GoQuery Selector is a selector used by https://github.com/PuerkitoBio/goquery
func (c *Collector) OnHTML(goquerySelector string, f HTMLCallback) {
c.lock.Lock()
if c.htmlCallbacks == nil {
c.htmlCallbacks = make([]*htmlCallbackContainer, 0, 4)
}
c.htmlCallbacks = append(c.htmlCallbacks, &htmlCallbackContainer{
Selector: goquerySelector,
Function: f,
})
c.lock.Unlock()
}
type htmlCallbackContainer struct {
Selector string
Function HTMLCallback
}
可以看出,整个方法的核心逻辑,就是基于入参传过来的选择器(goqueryselector string)和回调方法(f HTMLCallback),初始化一个内部结构 htmlCallbackContainer ,再追加到 htmlCallbacks 切片。
之后,收到返回结果是 HTML 的时候,Colly 都会遍历 htmlCallbacks 切片,使用选择器匹配页面元素,并将匹配中的页面元素封装成一个新的 HTML 标签即 HTMLElement 并执行回调方法。
func (c *Collector) handleOnHTML(resp *Response) error {
doc, err := goquery.NewDocumentFromReader(bytes.NewBuffer(resp.Body))
for _, cc := range c.htmlCallbacks {
i := 0
doc.Find(cc.Selector).Each(func(_ int, s *goquery.Selection) {
for _, n := range s.Nodes {
e := NewHTMLElementFromSelectionNode(resp, s, n, i)
cc.Function(e)
}
})
}
}
// HTMLElement is the representation of a HTML tag.
type HTMLElement struct {
// Name is the name of the tag
Name string
Text string
attributes []html.Attribute
// Request is the request object of the element's HTML document
Request *Request
// Response is the Response object of the element's HTML document
Response *Response
// DOM is the goquery parsed DOM object of the page. DOM is relative
// to the current HTMLElement
DOM *goquery.Selection
// Index stores the position of the current element within all the elements matched by an OnHTML callback
Index int
}
由此可见,注册多个回调方法,会按照注册的顺序逐个执行 for _, cc := range c.htmlCallbacks,并且每个回调方法对应的选择器如果命中页面中多个元素,那么同样是一个个元素调用注册方法 doc.Find(cc.Selector).Each 。
实现网络刮削器(Web Scraping)常用方法
Colly 封装 goquery 对外提供 HTMLElement 结构体,允许通过选择器匹配网页中的内容。
Colly 封装并提供了一些常用方法,可以简化刮削流程:
Attr(k string) string:返回元素指定属性,没有就返回空字符串,比如常用的e.Attr("href"),获取元素的 href 属性,一般是 a 标签的链接ChildText(goquerySelector string) string:拼接goquerySelector匹配的子元素的文本内容,比如e.ChildText("body > h1 > span")ChildTexts(goquerySelector string) []string:以切片格式返回goquerySelector匹配的子元素的文本内容ChildAttr(goquerySelector, attrName string) string:返回goquerySelector匹配的第一个子元素的attrName属性ChildAttrs(goquerySelector, attrName string) []string:以切片格式返回goquerySelector匹配的所有子元素的attrName属性ForEach(goquerySelector string, callback func(int, *HTMLElement)):遍历goquerySelector匹配元素,并对其执行callback函数,比如table.ForEach("tbody > tr", func(_ int, tr *colly.HTMLElement) { speach := tr.ChildText("td") }),就是遍历一张表格(table)下所有 tr 标签("tbody > tr"),然后对每一个 tr 执行回调方法,获取子元素 td 的拼接文本ForEachWithBreak(goquerySelector string, callback func(int, *HTMLElement) bool):跟ForEach非常相似,但是可以通过在回调函数中返回 false 来中断遍历
实现 English Pod 网站爬虫
首先要观察页面内容,确认想要哪些信息。比如下图是 English Pod 系列存档内容,链接是: English Pod 0001 Diffcult Customer 。

为此,设计出结构体用于存放信息:
type EnglishPodContent struct {
Title string // 标题
SerialNo string // 序号
AudioClip string // 音频文件链接
Dialogue []string // 对话
KeyVocabulary []VocabularyItem // 关键词汇
SupplementaryVocabulary []VocabularyItem // 补充词汇
}
type VocabularyItem struct {
Vocabulary string // 单词
PartOfSpeech string // 词性
Meaning string // 词义
}
接下来,通过控制台查看 HTML 页面布局,写好选择器,提取出想要的内容。
标题:
englishpodContent.Title = e.ChildText("body > h1 > a")
序号以及音频文件链接:
因为只需要数字,所以还需要将拿到的文本做正则匹配剔除掉括号。然后,音频文件是固定的链接前缀带上不同的序号,所以可以一并组装出来。
serialNoRawString := e.ChildText("body > h1 > span")
serialNoRegex := regexp.MustCompile(`\(.*(\d{4})\)`)
serialNoMatchArr := serialNoRegex.FindStringSubmatch(serialNoRawString)
if len(serialNoMatchArr) >= 2 {
englishpodContent.SerialNo = serialNoMatchArr[1]
englishpodContent.AudioClip = fmt.Sprintf("https://archive.org/download/englishpod_all/englishpod_%sdg.mp3", englishpodContent.SerialNo)
}
对话,关键词汇,补充词汇,在页面中都是表格(table)形式展示,那么从层级结构上可以遍历页面上的表格,然后按照顺序逐一提取出这三个信息。
e.ForEach("table", func(inx int, table *colly.HTMLElement) {
// 对话
if inx == 0 {}
// 关键词汇
if inx == 1 {}
// 补充词汇
if inx == 2 {}
})
对话:
一行存储一个元素,最终是以切片的形式存储。通过 "table > tr" 选择器,可以遍历表格下每一行数据,它一行数据下就是两个 <td> 标签:
<tr>
<td>A: </td>
<td>Good evening. My name is Fabio. I'll be your waiter for tonight. May I take your order?</td>
</tr>
我只想将这两个标签文本拼接起来就可以,所以使用 ChildText("td"),这样得到文本就是:A: Good evening. My name is Fabio. I'll be your waiter for tonight. May I take your order?。具体实现如下:
if inx == 0 {
dialogue := make([]string, 0)
table.ForEach("tbody > tr", func(_ int, tr *colly.HTMLElement) {
speach := tr.ChildText("td")
if len(speach) > 0 {
dialogue = append(dialogue, speach)
}
})
englishpodContent.Dialogue = dialogue
}
关键词汇、补充词汇:
这两个信息页面结构相同,实现也是一样的。一个 <tr> 标签三个子元素 <td> ,分别存放了:单词、词性、词义。除了单词以外,另外两个有可能是空的。我这里是将这三个元素分别提取然后存放在三个字段,对应的是:Vocabulary、PartOfSpeech、Meaning。
if inx == 1 {
keyVocabulary := make([]VocabularyItem, 0)
table.ForEach("tbody > tr", func(_ int, tr *colly.HTMLElement) {
tmp := VocabularyItem{}
tmp.Vocabulary = tr.DOM.Children().Eq(0).Text()
tmp.PartOfSpeech = tr.DOM.Children().Eq(1).Text()
tmp.Meaning = tr.DOM.Children().Eq(2).Text()
keyVocabulary = append(keyVocabulary, tmp)
})
englishpodContent.KeyVocabulary = keyVocabulary
}
至此,页面解析部分就完成了,得到了 Go 结构体变量: englishpodContent。填充内容后如下所示:
{
"Title": "Elementary - Difficult Customer",
"SerialNo": "0001",
"AudioClip": "https://archive.org/download/englishpod_all/englishpod_0001dg.mp3",
"Dialogue": [
"A: Good evening. My name is Fabio. I'll be your waiter for tonight. May I take your order?",
"B: No, I'm still working on it. This menu isn't even in English. What's good here?",
"A: For you sir, I would recommend spaghetti and meatballs.",
"B: Does it come with coke and fries?",
"A: It comes with either soup or salad and a complimentary glass of wine, sir.",
"B: I'll go with the spaghetti and meatballs, salad and the wine.",
"A: Excellent choice. Your order will be ready soon.",
"B: How soon is soon?",
"A: Twenty minutes?",
"B: You know what? I'll just go grab a burger across the street."
],
"KeyVocabulary": [
{
"Vocabulary": "grab",
"PartOfSpeech": "principle verb, present simple",
"Meaning": "get quickly"
},
{
"Vocabulary": "go with",
"PartOfSpeech": "phrase",
"Meaning": "to choose, pick"
},
{
"Vocabulary": "would recommend",
"PartOfSpeech": "",
"Meaning": "suggest"
},
{
"Vocabulary": "complimentary",
"PartOfSpeech": "Adjective",
"Meaning": "free"
},
{
"Vocabulary": "still working on",
"PartOfSpeech": "phrase",
"Meaning": "not yet completed, need more time"
}
],
"SupplementaryVocabulary": [
{
"Vocabulary": "impatient",
"PartOfSpeech": "",
"Meaning": "uncomfortable waiting, wanting to go"
},
{
"Vocabulary": "fast food",
"PartOfSpeech": "phrase",
"Meaning": "food prepared and served quickly"
},
{
"Vocabulary": "waitress",
"PartOfSpeech": "common noun, singular",
"Meaning": "female server at a restaurant or bar"
},
{
"Vocabulary": "fancy",
"PartOfSpeech": "Adjective",
"Meaning": "nice, expensive, up-scale"
},
{
"Vocabulary": "casual",
"PartOfSpeech": "Adjective",
"Meaning": "relaxed, not dressy"
}
]
}
在此基础上,需要将上述提取的步骤,封装成一个回调方法,注册到 Colly 的 OnHTML ,这就实现了一个刮削器。每当,网络爬虫抓取到一个页面,就可以交给刮削器进行处理,并得到一个内存结构体,用作后续使用。
所以,一共创建了两个收集器(Collector),第一个主要负责爬虫功能,它解析页面提取出跳转链接,并将目标链接交给第二个收集器;第二个收集器主要负责内容刮削,打开目标链接页面之后,应用回调方法提取出所要内容。
// 负责爬虫
c := colly.NewCollector()
// 负责刮削
contentCollector := c.Clone()
c.OnHTML("a.stealth.download-pill[href*=html]", func(e *colly.HTMLElement) {
contentCollector.Visit(e.Request.AbsoluteURL(e.Attr("href")))
})
contentCollector.OnHTML("body", func(e *colly.HTMLElement) {
})
为了后续使用,现在将拉取下来的内容,以 markdown 格式文件存储下来,一篇音频对话文本是一个网页链接对应到一个文件。
因为,单词、词性、词义三个部分的字符长度不定,甚至还有空的情况,直接写入文件内容会错乱,为此使用 tabwriter 对齐三列数据,预览 markdown 的时候,呈现效果会好看一些。
func tabWriterPaddingVocabulary(vocabularyList []VocabularyItem) string {
if len(vocabularyList) <= 0 {
return ""
}
var (
contentBuffer bytes.Buffer
w = tabwriter.NewWriter(&contentBuffer, 0, 0, tabPadding, ' ', 0)
)
for j := 0; j < len(vocabularyList); j++ {
_, err := fmt.Fprintf(w, "**%s**\t%s\t%s\n", vocabularyList[j].Vocabulary, vocabularyList[j].PartOfSpeech, vocabularyList[j].Meaning)
if err != nil {
fmt.Println(err)
continue
}
}
w.Flush()
return contentBuffer.String()
}
最终抓取下来的效果如下所示,文件名称:“English Pod 0001 Elementary - Difficult Customer.md”:
## Audio Clip
[Audio Clip 0001](https://archive.org/download/englishpod_all/englishpod_0001dg.mp3)
## Dialogue
A: Good evening. My name is Fabio. I'll be your waiter for tonight. May I take your order?
B: No, I'm still working on it. This menu isn't even in English. What's good here?
A: For you sir, I would recommend spaghetti and meatballs.
B: Does it come with coke and fries?
A: It comes with either soup or salad and a complimentary glass of wine, sir.
B: I'll go with the spaghetti and meatballs, salad and the wine.
A: Excellent choice. Your order will be ready soon.
B: How soon is soon?
A: Twenty minutes?
B: You know what? I'll just go grab a burger across the street.
## Key Vocabulary
**grab** principle verb, present simple get quickly
**go with** phrase to choose, pick
**would recommend** suggest
**complimentary** Adjective free
**still working on** phrase not yet completed, need more time
## Supplementary Vocabulary
**impatient** uncomfortable waiting, wanting to go
**fast food** phrase food prepared and served quickly
**waitress** common noun, singular female server at a restaurant or bar
**fancy** Adjective nice, expensive, up-scale
**casual** Adjective relaxed, not dressy
最后,传入 English Pod 归档网帐的入口地址,就可以耐心等待爬虫将 365 个音频对话文件爬取下来。
fmt.Println("crawling...")
c.Visit("https://archive.org/details/englishpod_all")
完整示例代码,可在进入代码仓储 a-english-pod-crawler-in-go 中查看。
总结
通过本篇文章,可以了解以下三点内容:
- Colly 基础用法,对收集器、回调方法等等概念有基本的认知
- 如何使用 Colly 实现网络爬虫和网络刮削器,特别要知道如何处理 HTML 返回结果
- 如何分析页面结构,自定义结构体,存储页面信息